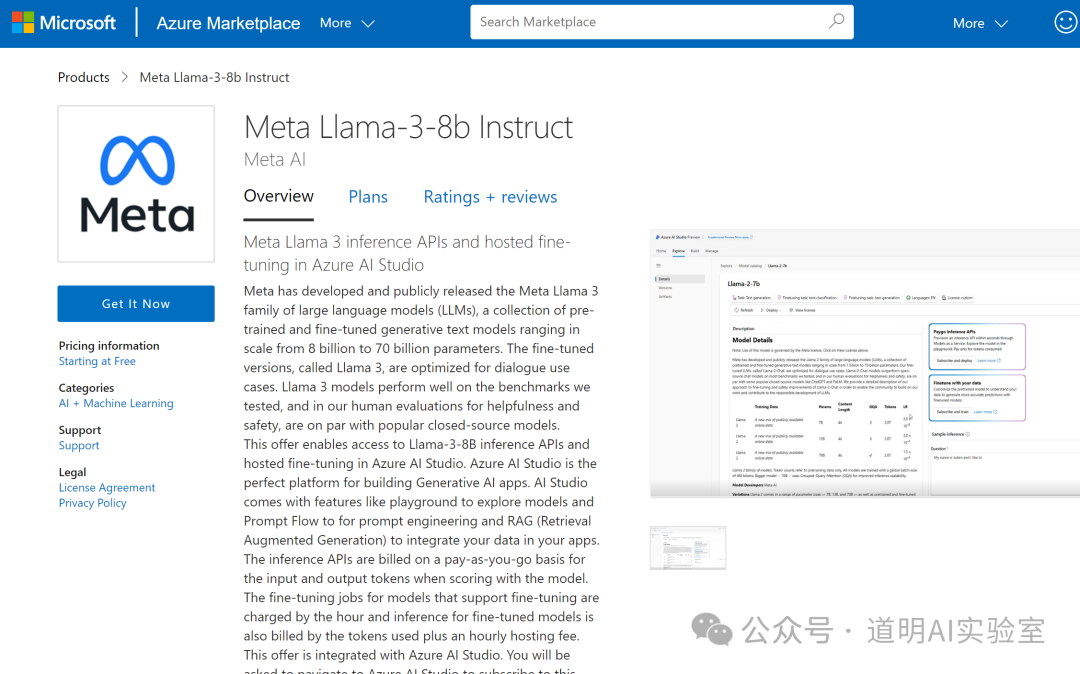
The story goes like this: suddenly, this interface appeared on Microsoft Azure Cloud:
Then people started asking on social media if it was actually released. It's unclear if Meta's rapidly rising stock price at that moment was stimulated by this news.
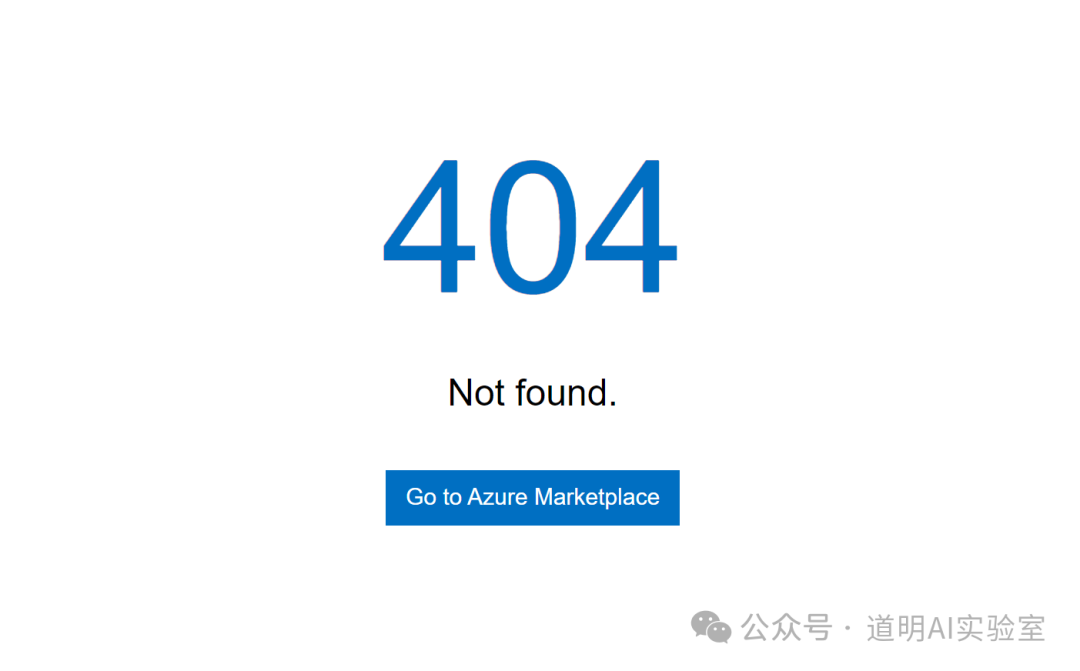
However, when I logged in, it first showed no related resources, and after a few refreshes, it was back to the familiar state (empty).
Furthermore, visiting various Meta-related websites revealed no official news about the Llama-3 release. No additional information could be obtained from social media beyond the page shown above.
This was an "oopsie." However, it's more likely that Llama-3 might actually be released by the time we wake up.
Regardless, we can seriously analyze the key points from the information above:
- The model's parameter scale is 8B-70B, with a pre-release 8B fine-tuned instruct version for preview;
- In tests, the model performed well, and in subjective evaluations, it even reached the level of closed-source models (are they referring to GPT-4?);
Other speculations:
- Llama-3, as a model family, will have many versions and will start rolling out from now on;
- Multimodal and MoE? Everything that should be there will come eventually. It's time for Meta to perform.
In fact, the open-source Llama-3 is what more people are eagerly anticipating.
The expected GPT-5 represents the ceiling, but Llama-3 is the "inclusive" floor that can truly bring more productivity scenarios to fruition. Here is an excerpt from a previous article:
Is open source just for being free?
Open Source originally referred to making source code open. Its true meaning is that through open code usage, all developers (whether or not they have contributed to the open source project) form a mutual aid model: 1. For many common basic functions or difficult problems, one doesn't have to start from scratch, which significantly improves efficiency; 2. Because the source code is open, problems and bugs in the program are easier to discover and fix early. Although open code allows ill-intentioned individuals to look for vulnerabilities in widely used code to find ways to "attack," it is also because the code is open that the speed of fixing "security vulnerabilities" becomes very fast: the spear and the shield are always complex, co-existing sides.
Today's AI open source is rarely "Open Source" in the complete sense anymore, because that would mean not only the full opening of training code but also the full opening of training data: a model is a specific result obtained from specific data through a specific training program on specific hardware. Although some projects still achieve full openness in the above sense, it is generally accepted that an open-source model at least provides a public download of the model weight files (whether it can be used commercially without restriction or only for non-commercial research depends on the provider's commercial agreement).
One could say that for today's AI models, regardless of the provider, the greatest contribution comes from the open-source community. This is not only because the well-known Transformer architecture is open, but also because many ideas and tools used in training models are open-source, and the vast majority of basic data is also open. Without the open-source community, there would be no generative AI as we know it today.
Therefore, the claim by some that "closed source is better" is actually baseless: we can make a poor closed-source model, or we can make a great model and then close it or even charge for it. The distinction between open and closed source is not due to model quality; at most, it's about the outcome: because better models often require more investment, and users are more willing to pay for better models.
Of course, for many startups, providing an open-source solution is often the core of the product, while they charge for a full suite of products developed around that core (such as more user-friendly interfaces, lower barriers to entry, more extended functions, better service support, etc.). This has been a very popular method for the past decade, and now, in the era of AI models, some companies are adopting this approach. While open source objectively serves as advertising and a lead generator, its more long-term and profound effect is that a truly good product core (code modules or current models) can attract more developers to help improve it, jointly enhancing and enriching the core's capabilities, creating a virtuous cycle. Developers don't use it just because it's open source; they are willing to provide feedback and improvements within an open-source ecosystem because of a good program or model, making it even better.
Although examples of excellent open-source projects being terminated due to the limited energy of core developers and maintenance costs are common, the most frequent result is that more enthusiasts or even commercial companies are willing to take over the improvement and maintenance work.
There are also many cases where commercial companies see the potential of a project and develop a closed-source paid version on its basis, while other developers are willing to carry the torch and continue the open-source mission.
Today's AI is another sturdy tree growing out of the open-source ecosystem. The largest number of excellent programmers are not in those tech giants; rather, many excellent programmers within tech giants are active in various open-source communities. Everyone draws nourishment from and gives back to the open-source world.
Perhaps a more appropriate expression is: open source and closed source are not opposing contradictions; closed source is merely a subset of the programming world, but that programming world itself is open source.