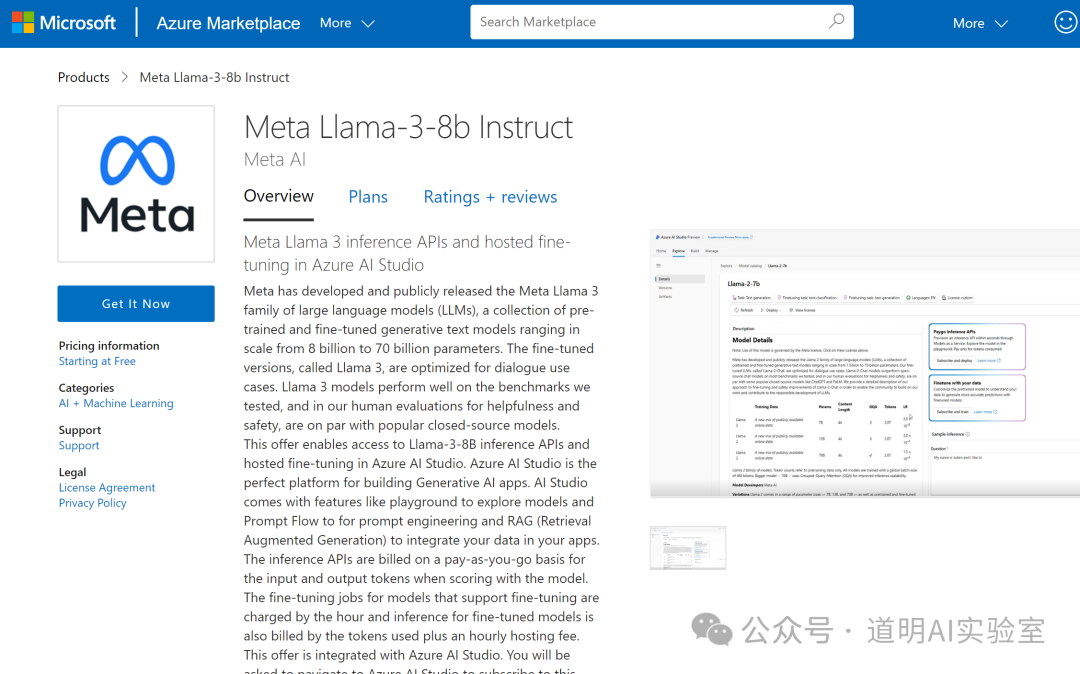
事情是这样的,突然,在微软Azure云上就出现了这样的界面:
然后就是大家开始在社交媒体上询问,是不是真的出来了。也不知道此刻正在快速拉升的Meta股价是不是受到了这条消息的刺激。
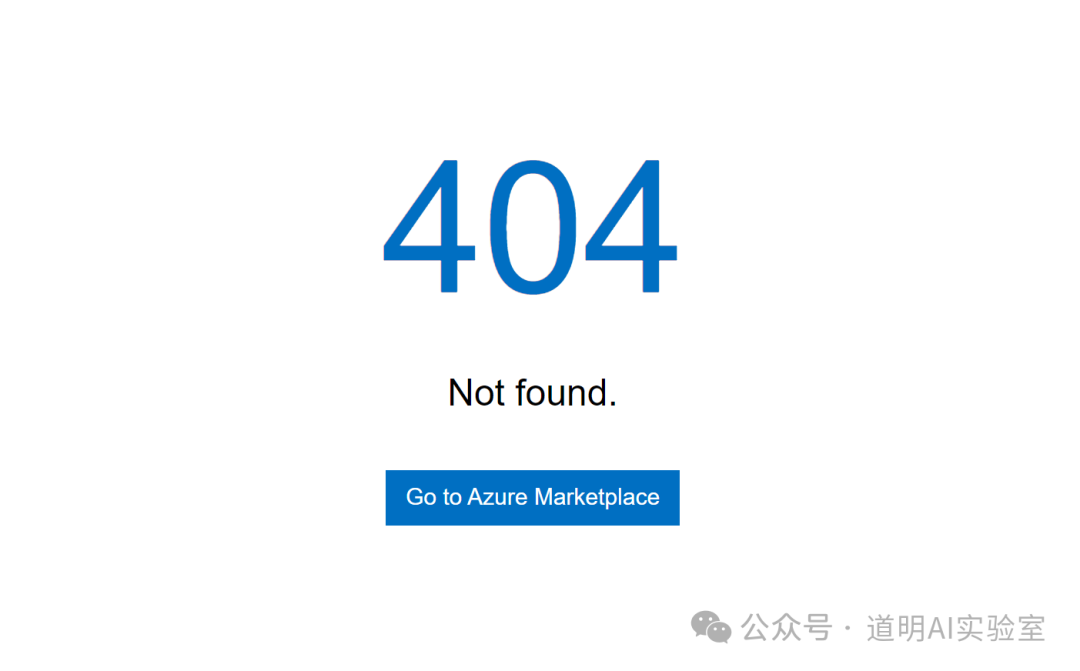
但是,当我登录以后,先是显示没有相关的资源,刷新了几次之后,就是我们熟悉的配方了。
除此之外,去meta相关的各网站,都没有任何关于LLaMa-3发布的官方消息。社交媒体也没有除了上面页面外更多的信息可以获得了。
这是一次“乌龙”。但是,更大的可能是,也许一觉醒来,LLaMa-3真的就发布了。
无论如何,我们可以通过上面的信息认认真真的分析一下要点:
1、模型的参数规模是8B-70B,预发布8B的精调instruct版本供预览; 2、在测试中,模型表现良好,主观评价里,甚至达到了闭源模型的水平(说的是GPT-4吗?);
其他推测:
1、LLaMa-3模型作为一个家族,会有不少版本,现在起开始滚动发布; 2、多模态和MoE?该有的,慢慢的都会有的。轮到meta表演的时间段了。
其实,开源的LLaMa-3,才是更多人期待的。
期待中的GPT-5是天花板上限,LLaMa-3却是真正能够带来更多生产力场景落地的“普惠”下限。附一段之前文章的部分内容:
开源只是为了免费吗?
开源,Open Source,最早是指开放源代码。它真正的意义是,通过代码开放使用,使得所有开发者(无论是否对开源做出过贡献)都形成一种互助模式:1、对于很多常用的基础功能或者难题,不必全部从头做起,大幅提升效率;2、因为源代码开放,所以对于程序的问题和bug更容易被发现,也更容易尽早被修复。虽然,因为代码开放,别有用心的人会盯着使用多的代码寻找漏洞,从而找到“攻击”的方式,但也正因为代码开放,修复“安全漏洞”的速度也变得很快:矛与盾总是复杂的伴生双面。
如今的AI开源,已经很少有完全意义上的Open Source了,因为这不仅意味着训练代码的完全开放,还意味着训练数据的完全开放:模型是特定数据通过特定训练程序在特定硬件上得到的特定结果。虽然还是存在一些项目,是做到上述意义的完全开放的,但是大家普遍认为的开源模型,就是至少提供模型权重文件的公开下载(是否可以商业无限制使用,还是只能作为非商业的研究使用,则要看模型提供方的商业协议约定)。
可以这么说,如今的AI模型,无论是哪一家的,贡献最大的就是开源社区。不仅仅是因为大家熟知的transformer架构是开放的,也因为在训练模型中用到的很多想法和工具都是开源的,更因为绝大部分的基础数据也是开放的。没有开源社区,就没有如今的生成式AI。
所以,有些人宣扬的“闭源更好”,其实,是没有依据的:我们可以做一个很差的闭源模型,我们也可以做一个很好的模型,然后闭源,甚至收费。开源与闭源,根本不是模型质量的原因,最多,是结果的部分:因为更好的模型往往投入更多,更好的模型用户也更愿意付费。
当然,对于很多初创公司而言,提供一个开源的方案,往往是产品的核心部分,同时提供围绕核心开发出的整套产品(例如更友好的界面,更低的使用门槛,更多的扩展功能,更好的服务支持,等),进行收费。这确实是过去十多年,非常流行的一种方式,如今,到了AI模型时代,一些企业也开始采用这种方式。虽然,客观上,开源起到了广告和引流的作用,但是更长期影响更深远的作用是:真正好的产品核心(代码模块,或者现在的模型)可以吸引更多的开发者一起来帮助改进,一起提高和丰富核心的能力,形成良性循环。开发者不会因为开源而使用,却会因为好的程序或者模型愿意在开源生态下反馈和改进,从而变得更好。
虽然,因为核心开发人员精力和维护成本问题,优秀开源项目不得不终止的例子屡见不鲜,但是伴随而来结果最多的也往往是更多有志之士甚至商业化公司愿意承接起项目的改进和维护工作。
也有不少的例子是,商业化公司看到了项目的潜力,在这个基础上发展出了闭源收费版本,同时,却也有别的开发者愿意扛过继续维护的大旗,继续着开源的事业。
如今的AI,是开源生态里长出的又一棵茁壮大树。最大量的优秀程序员并不在那些科技巨头里,科技巨头里也有大量的优秀程序员活跃在各大开源社区中。每个人都从开源世界里吸取养分并回馈。
或许,更合适的表述是:开源与闭源不是对立的矛盾体,闭源只不过是程序世界里一个子集而已,这个程序世界,却是开源的。