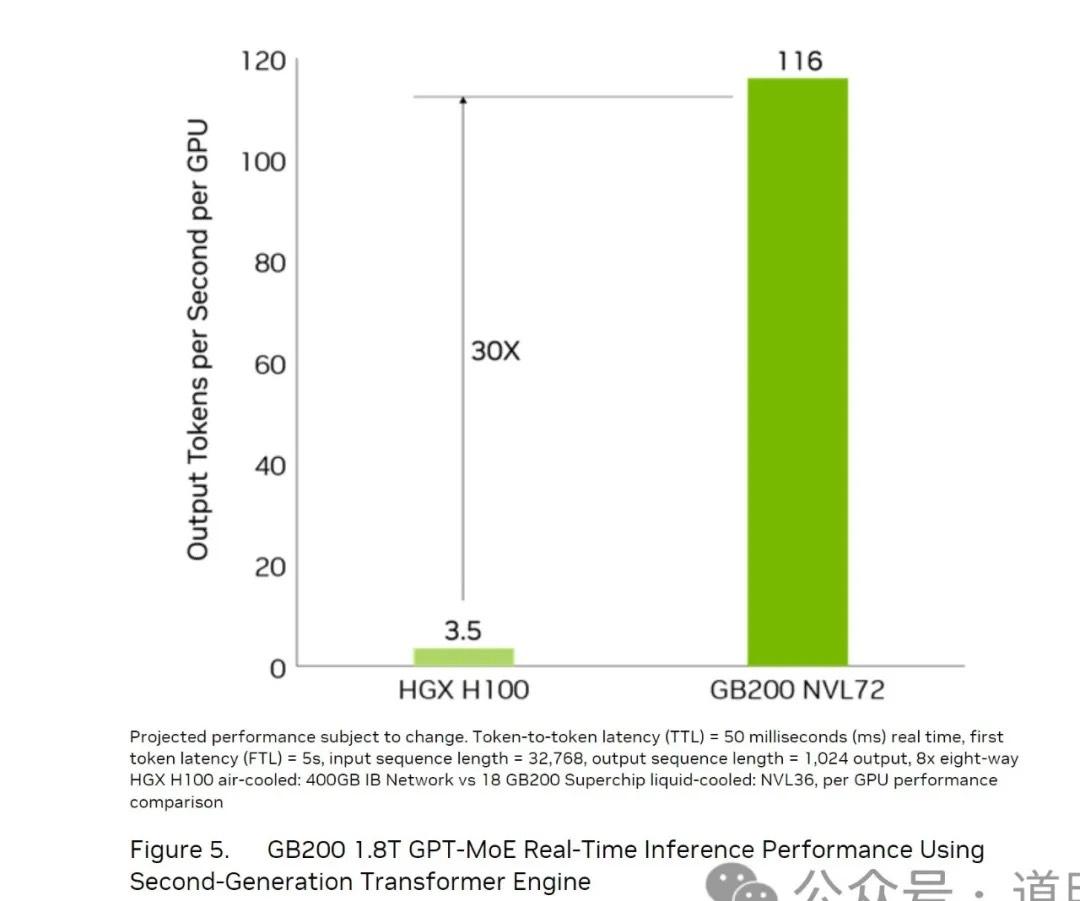
在英伟达官网给出的最新Blackwell架构的材料里,关于推理性能的提升有下面一张图,明确给出了一个结论,选用GB200 NVL72方案,推理性能是H100的30倍(每GPU)。
当然,这样的提升是在一定的假设之下:输入32768tokens,输出1024tokens;每个用户请求在5s后开始输出第一个token。
虽然这是一个非常理想化的假设。因为在设定的配置里(H100是通过单机八卡方式连接,GB200是用最新的NVL72方式),这种方式对于H100并不友好:由于互联性能的关系,在这样的配置里,H100能够支持的高并发显著低于GB200NVL72,因此,5s的首token延迟对H100系统的影响要大的多。
但是,我们依然可以看到,如果应用到推理时,NVL72这种连接方式的价值所在:当单die的能力很难再提高时,显然系统能力就变得更加重要了。
下面就按各环节简单的过一下,30倍性能提升如何得来,因为实际的影响其实要经过复杂的计算,所以下面都用最简单的计算方法,误差不至于影响结论。
1、FP8与FP4:2x
Blackwell架构开始支持FP4,而H100对应的Hooper架构还是FP8,英伟达给出的测算,GB200系统用的是FP4,H100系统用的是FP8,简单而言,这给推理带来了2x的性能表现。
所以,如果不考虑精度变化带来的影响的话,30倍变成15倍。
2、各种并行:HBM带宽与铜互联
单GPU内存方面,GB200升级到了HBM3e,每个GPU对应八个HBM stack,每个stack是24GB,每个stack有1TB/s,所以整体内存带宽达到8TB/s,上一代最高是4.8TB/s。在“内存墙”的作用下,我们几乎可以认为推理的速度首先受到内存带宽影响,所以,在单GPU下,性能提升应该是67%(8/4.8-100%),或者1.67x。
并联:NVLink升级到了第五代,带宽提升一倍,从900GB/s到了1800GB/s。这当然作用非常大,但是,新的NVLink连接方式下的NVL72其实带来的最大改变是内存的池化(GH200开始的):当内存池化时,并行下,内存带宽就不是上面说的8TB/s,而是N*8TB/s(N为GPU数量),所以,英伟达给出的GB200 NVL72的HBM带宽是576TB/s。
这个作用在哪里?池化后,用于推理的模型可以通过tensor并行,加上模型的MoE架构,模型权重可以并行分配到若干个GPU中(假设16个)并行计算(在一次推理时,不需要相互等待),所以实际带宽应该是16*8TB/s,即128TB/s。
对于H100/200的这种架构,英伟达没有强调这种概念,但因为8卡的DGX内部也是NvLink连接的,所以理论上可以达到最高8*4.8TB/s=38.4TB/s。128/38.4=3.33x。如果对照回英伟达的比较基准H100,HBM带宽是3.3TB/s,所以,实际上是128/3.3/8=4.8x。
但是,如果考虑到使用H100/H200推理时,对于GPT-4这样大的模型,8卡是不够的,我们上面假设16卡,也是为了方便计算。在超过8卡的配置下,意味着推理时,对于H100/200的DGX系统,八卡的机器间互相是串联关系:一个完成需要等待另一个,这之间的连接速度就降到了NVLink的速度,第四代对应的900GB/s。
对于NVL72这样的配置,显然72卡可以轻松容纳GPT-4甚至下一代模型的推理。
当然,如果是16卡跑模型的配置下,一次推理,上一代NVLink的带宽900GB/s只限制了一次传输等待。根据各种资料看,整体对推理速度的影响从上面所说的4.8x到了8-10x左右。
其实,英伟达更早就意识到了这个问题,推出了GH200系统,256卡可以池化,但可能因为CPU不给力,可能因为发货太晚,也可能因为互联速度不够,相比理论极限有了巨大的折扣,所以,客户并不买单。
这一次的NVL72从技术上解决了不少问题。
综上,可能对于一个GPT-4这样级别的模型而言,不考虑精度下,得益于HBM带宽,特别是铜互联带来的更好的GPU池化效果,实际推理性能应该比上一代提升了8-10x(单GPU)。
那么,问题来了。从各项成本考虑,推理成本到底能下降多少?
客观讲,这其中的变量非常多,简单起见,就按照单GPU的性能提升来讨论,即GB200 NVL72配置下,同样精度下,单GPU推理能力是H100系统的8-10x。
市场上普遍预期,GB200系统下,虽然英伟达的成本至少翻倍,但是售价相比H100应该达不到翻倍这么多,假设从整个系统分担到单GPU,购置成本提高60-70%。
GB200下单GPU的能耗从H100的700W提升到1200W,从系统而言,一台八H100的DGX功耗是6500W,NVL72系统整体功耗的120KW。所以,DGX平均到每个GPU的功耗大概是812.5W,NVL72分配到每个GPU的功耗是1667W,不过,这里面没有考虑DGX使用IB网络连接时网络的能耗,所以,实际上H100的单功耗会比计算的更高。简单假设1000W,那么NVL72下单GPU功耗为1.67x,与购置成本增加差不多。
在摊销,电价一系列不变的假设下,NVL72下单GPU的成本差不多是1.67X。
所以,相同成本下,推理性能的提升为4.8-6x(8-10x/1.67x)。
也就是说:如果到了GB200 NVL72配置下,推理成本至少可以下降5倍。如果把精度下降到FP4,那么,就是10倍。
最后的takeaway:
1、到了GB200 NVL72时代,因为推理成本的显著下降,GPT-4推理应该可以从亏钱到挣钱(还取决于OpenAI的token费用下降多少);
2、显然,如果大模型能力更好,那么使用NVL72推理大模型,将比使用上一代架构推理小一点的模型,经济成本上优势更大;
3、模型上,两极分化的情况或许会更加严重,要么做到足够小但是质量够用,要么做到质量足够好但是规模也更大,中间路线,看起来越来越没什么竞争力。