Within two days, Databricks released DBRX and AI21 released Jamba—both are open-weight Mixture-of-Experts (MoE) models. This feels very much like a certain period last year: after closed-source models were launched one after another, open-source models began taking the stage to perform.
To be precise, this explosion of open-source models likely began with the Mixtral 8x7B MoE model last December. DBRX and Jamba seem to have drawn heavily from the Mixtral architecture. A direct piece of evidence is that DBRX was trained using 3,072 H100s, taking about three months for pre-training, fine-tuning, and red-teaming. The situation for Jamba is likely similar.
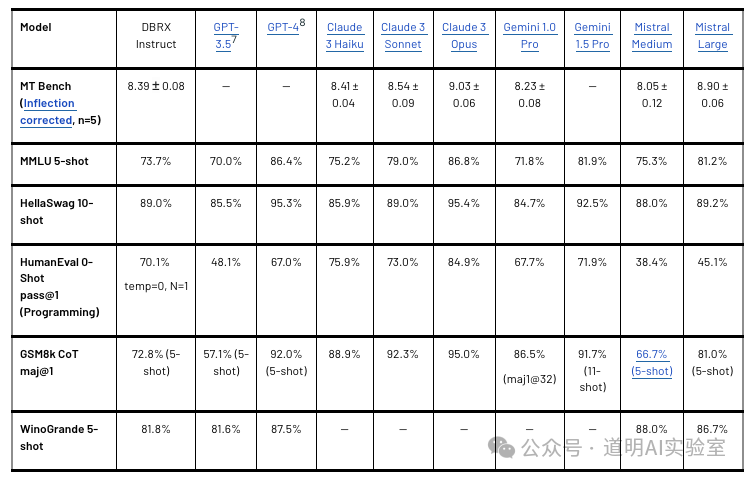
Based on benchmark scores, DBRX performs excellently even when compared to closed-source models, surpassing GPT-3.5 and performing at a level similar to Gemini 1.0 Pro.
Compared to other open-source models, DBRX clearly demonstrates superior performance.
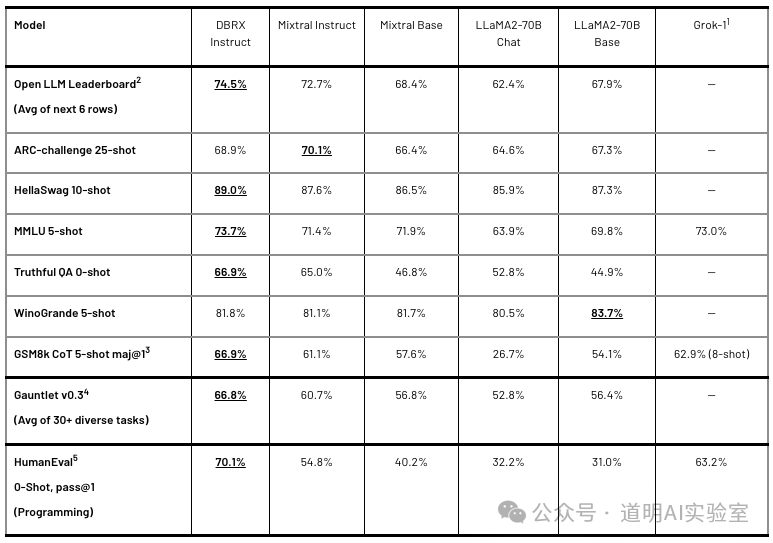
In comparison, Jamba performs slightly lower; however, the DBRX used for benchmarking is a 132B parameter model (with 36B active parameters), while Jamba is a 52B parameter model (with 12B active), representing a three-fold difference in scale. While both borrow from Mixtral, there are many new highlights beyond just performance gains.
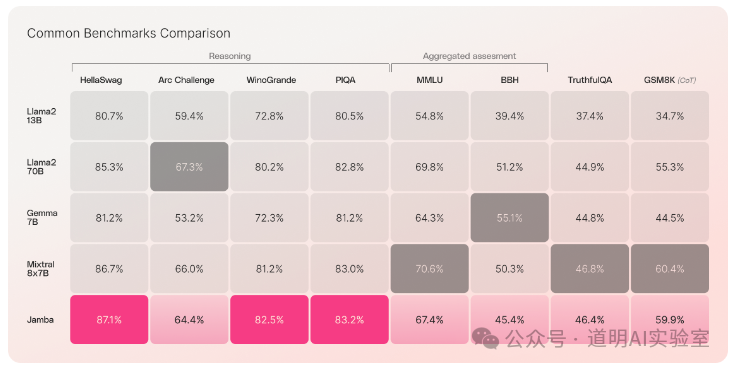
MoE has become mainstream. GPT-4 is MoE, Gemini 1.5 Pro is MoE, and the popular domestic model Kimi Chat is also MoE. Naturally, today's protagonists DBRX and Jamba are MoE as well. The quality improvements are quite obvious. Furthermore, MoE has the advantage of significantly lower training compute requirements for the same parameter scale.
Both DBRX and Jamba focus heavily on long context and RAG.
DBRX supports a context window of up to 32K. Jamba is the first Mamba-architecture model ready for production environments, supporting a context window of up to 256K.
Jamba has not specifically released long-context test results, while DBRX significantly outperforms GPT-3.5 in this area. However, judging from technical report details, I suspect its capability might not match Kimi's. This will require detailed comparison after I have time to deploy both models locally.
Regardless, long context is undoubtedly the most basic and vital capability for Large Language Models.
- Both models emphasize inference performance.
In this regard, Jamba is clearly more aggressive. First, in long-context scenarios, its token output per second is three times that of the Mixtral 8x7B model (even though the parameter counts are nearly identical).
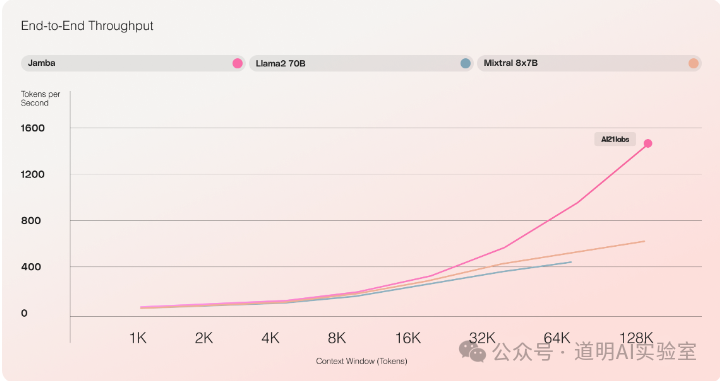
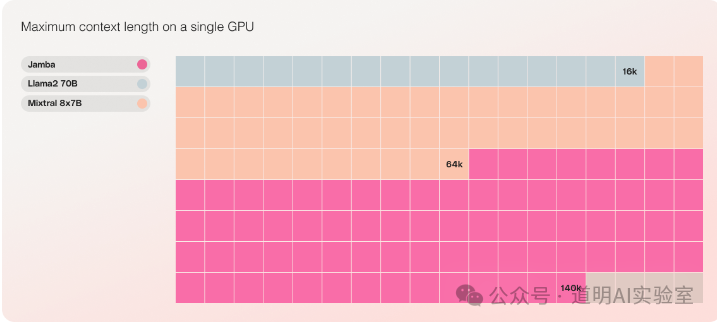
Secondly, Jamba can perform inference on a 140K context using just a single GPU (likely referring to an H100 80GB), whereas Mixtral only supports up to 64K and LLaMA2-70B only supports 16K. LLaMA-3 really needs to be released soon.
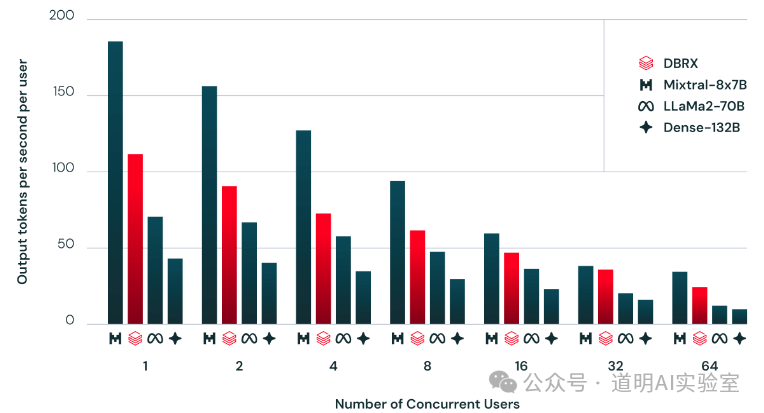
DBRX provides different comparisons. Under high concurrency (64 concurrent users), DBRX's output capacity is nearly double that of LLaMA2-70B, while the gap is not large compared to Mixtral, which has only one-third the parameters.
- Beyond MoE, long context, and inference performance, why are these two companies releasing these open models? (They are open-weight; Jamba uses the Apache 2.0 license, which is generally understood as open source without commercial restrictions, while DBRX uses Databricks' own open license. According to their terms, an additional license is required if monthly active users exceed 700 million.)
Databricks was already a leading SaaS provider for data and AI. Transitioning from SaaS to MaaS (Model as a Service) is a very viable business model. Databricks can provide small and medium enterprises (SMEs) or individuals with complete cloud-based private deployment and maintenance solutions based on their open-source models. The model itself is free, but infrastructure and supporting services can be monetized. The launch of DBRX ensures Databricks won't be quickly phased out in this wave of change; in fact, the model's performance suggests Databricks could stand to benefit.
As a top MaaS company in text generation, AI21's open-source models can further solidify its core business while expanding other cloud service opportunities. While my experience with AI21 is limited compared to my years using Databricks stacks, one thing is certain: in overseas markets, where user acceptance of SaaS and willingness to pay is high, the path to MaaS is clear. In contrast, the situation in China will be completely different.
- Regarding Inference.
Whether for closed or open models, AI has entered a stage of exploding inference demand. Deployment barriers (ecosystem), inference performance, and inference costs are the three most important factors.
Recently, both Stability AI and Databricks have published conclusions regarding inference. The consensus is that Intel's Gaudi2 is the most cost-effective inference card. On one hand, Gaudi2's inference performance exceeds the A100 and even outperforms the H100 in some scenarios. On the other hand, Gaudi2 has very low latency, and Intel's cloud service prices are relatively inexpensive.
Consequently, in the cloud inference market, Intel and even AMD appear attractive. Companies with strong technical capabilities like Stability AI and Databricks can easily handle inference across different hardware environments. But what about the internal inference needs of SMEs? Clearly, NVIDIA's ecosystem remains the most attractive due to lower technical barriers and more flexible application scenarios (SMEs may face rapid changes in technical environments; the CUDA ecosystem isn't just for LLM inference but can be flexibly switched to other use cases).
Of course, the inference market differs significantly between domestic and international contexts. Overseas, B-end users have high acceptance of cloud services, and business implementation is the primary consideration, so they often choose integrated solutions from SaaS providers. This is even more apparent in the deployment of open-source (or private closed-source) models. Basic cloud providers (AWS, Azure, Google Cloud) purchase diverse hardware in bulk and offer complete SaaS stacks. For users of SaaS companies like Databricks, hardware lock-in is weak; everything is one-click deployment in the cloud. Whether inference runs on NVIDIA, Intel, or AMD, cost may become the sole deciding factor.
In China, even when users choose cloud services, they tend to opt for bare metal servers, with SaaS adoption being significantly lower than overseas. Hardware architecture and ecosystem support become critical factors. Of course, if data center rental and electricity costs are right, buying cards is still the preferred choice. Today, GPUs are practically a hard currency, potentially holding value better than real estate.
From this perspective, Lenovo's recent hint that AMD MI300 shipments exceeded expectations, combined with reports from various channels that H20 orders exceeded expectations, both seem quite logical.
In fact, there are many other choices for inference, such as the hyped AIPC, smartphones, and other edge devices. We'll see them roll out scenario by scenario. For at least the next two or three months of this half-year, the focus should remain on LLM inference.