
Stability AI Releases SV3D: A Leap Forward in Generating 3D Information from a Single Image
Stability AI has released a new model titled "Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion." In plain terms: by inputting a single image and utilizing their proprietary video generation model, it can generate the 3D information of an object—or more accurately, projected images from various spatial perspectives.
Since the weight files for this model are directly downloadable, meaning it can be run locally for non-commercial purposes, I ran it locally to explain the general structure and concepts of the model based on the results.
1. Local Model Testing Process
I randomly searched for a PNG image of a penguin. The reason for choosing this one was simple: clear subject, transparent background, and cute.
Downloaded weight files from Hugging Face: there are two versions,
sv3d_uandsv3d_p, each around 9.36GB and 9.37GB respectively. They are slightly smaller than SVD (Stable Video Diffusion), which is expected as SV3D leverages the SVD model.
- For local execution, a Python environment is naturally required, specifically PyTorch with CUDA support (it specifically required Python 3.10, PyTorch 2.0.1, and CUDA 11.8/12.1—though the source mentioned 18.1, I encountered some detours before successfully running it in these environments), Transformers, and a series of other packages.
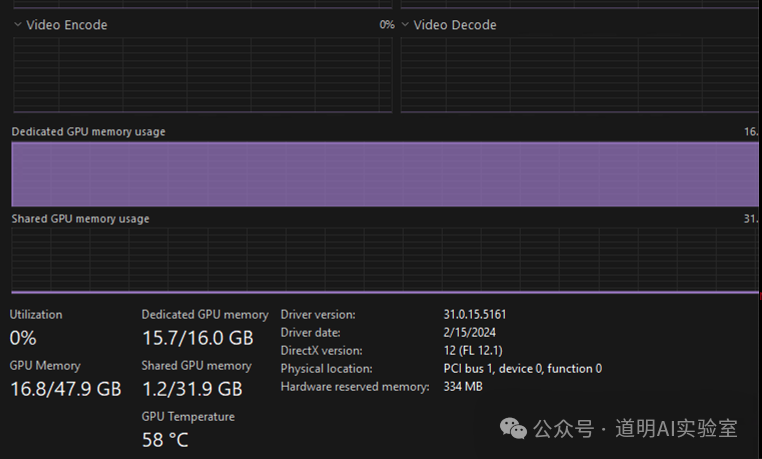
During execution, the model loaded into VRAM, filling the 16GB VRAM of my test environment and even utilizing some shared memory, which slowed down the generation speed.
- The input was the single PNG above, and the output was a series of images from different perspectives, all at a resolution of 576x576.
I set the parameter to 21 images.

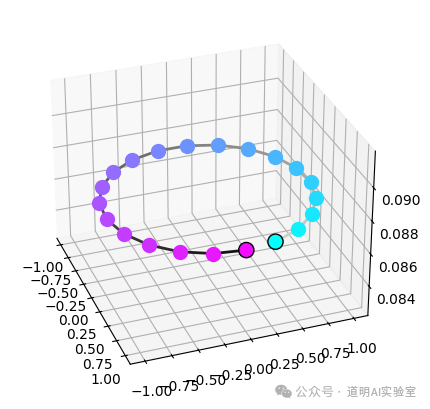
To view it more intuitively, the image below shows the spatial positions of these different perspectives.
- The above covers essentially all of the SV3D model. However, to verify the results, the paper also introduces a 3D reconstruction step, which I also ran. The basic idea is simple: use the 21 multi-view images to reconstruct a 3D model, rotate it, and output a video. Even though it starts from a single photo and has some artifacts (like the gray matrix at the bottom middle), it is a massive improvement. Furthermore, the model supports multi-image input; this is why there are two models,
sv3d_uandsv3d_p. The_psuffix supports dynamic orbits, meaning it achieves better results through multiple image inputs.

2. Model Architecture
- The basic structure of the model is shown in the image below: it utilizes a diffusion video model, and the training data consists of 3D model rotation videos (divided into static and dynamic orbits, as shown in the right image below). During inference, it takes one or a few images and outputs a 3D rotation video of the object, which is then "sliced" to obtain multi-angle static images.
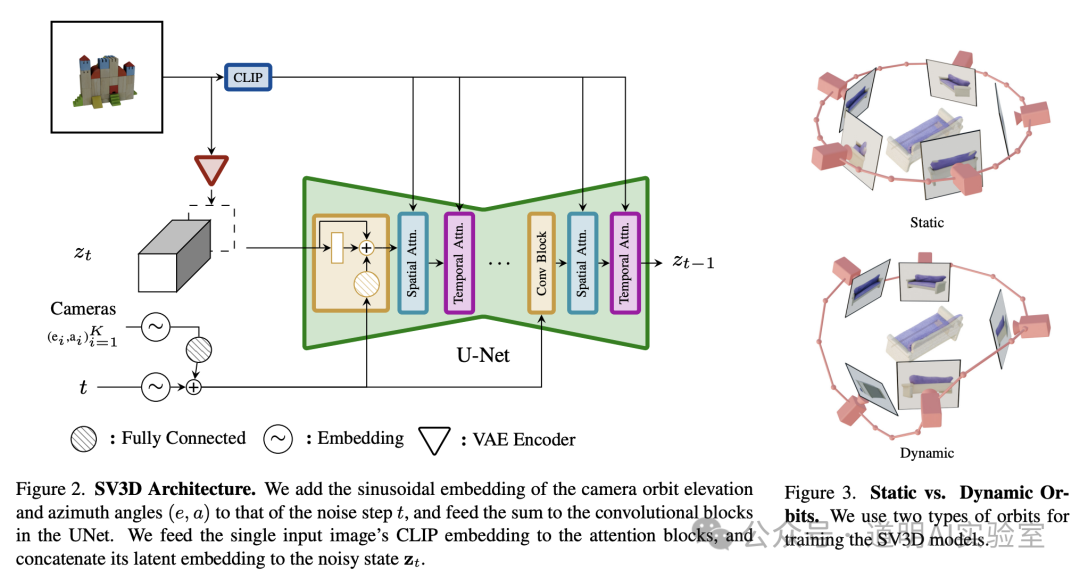
Because the core is video diffusion, it still uses a convolution-based U-Net rather than the DiT (Diffusion Transformer) found in Sora or Stability AI's own Stable Diffusion 3 (though it will surely be used in the future, perhaps in a "Stable Video Diffusion Transformer"). The generated image (video) resolution is 576x576, which will likely increase, though moving to 1024x1024 would significantly increase model scale.
- To perform 3D reconstruction from the generated perspectives, two additional models are used: NeRF (NVIDIA's Instant-NGP version) for generating a coarse 3D model, followed by DMTet (also by NVIDIA) to generate a higher-precision 3D model. This part is not the core of SV3D but serves as verification.
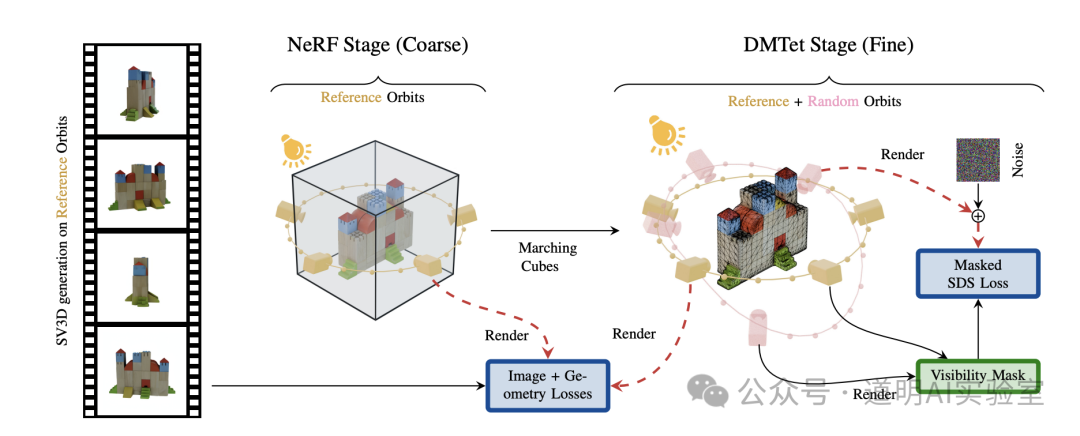
3. Conclusion
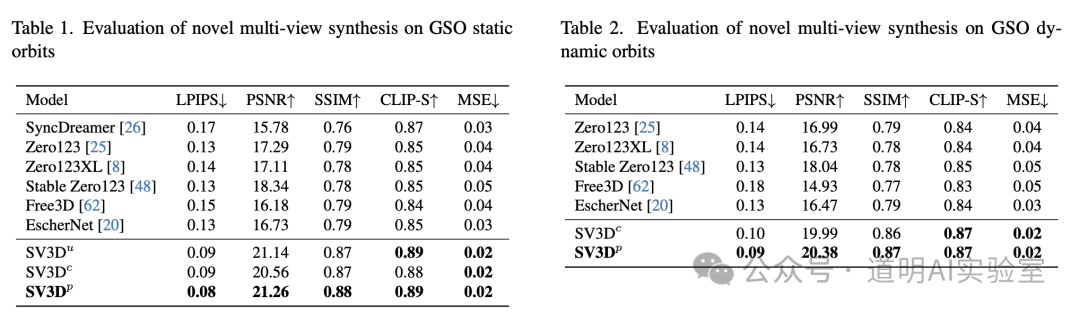
- Based on both benchmark scores and my actual tests, it is indeed the best model currently available for generating 3D from a single image.

Application Scenarios: This model can be quickly applied to game design and AR/VR development. With its 576x576 resolution and some optimization, it can rapidly provide a large volume of 3D assets.
Progress in 3D Generation: If we look at the complete application chain: Text-to-Image -> Text-to-Video -> Image/Video/Text-to-3D, Sora has completed the first two steps, roughly corresponding to the level of ChatGPT at its release in late 2022, or perhaps a year earlier, between GPT-2 and GPT-3. Current 3D models are about one to two years behind. This means 3D AIGC will reach its "ChatGPT moment" in about 2-3 years. This is not slow at all; in fact, it aligns with the maturity timeline of AR/VR headsets.
The significance of mastering 3D goes beyond gaming and entertainment. It is the next critical step in what I consider "World Models." Although Sora generates video, it already possesses high spatial consistency. We can generate 3D models based on Sora outputs using the concepts from SV3D—a concept I have discussed and demonstrated in previous articles. Currently, OpenAI and Stability AI (likely backed by their deployed 4,000 Intel Gaudi2 GPU cluster) are progressing the fastest in this field. Their goals and paths differ slightly: Sora is not primarily for video generation, whereas the Stable Diffusion series is explicitly for generating images, videos, and 3D. Sora aims for maximum video quality in one step, while Stability focuses on making the end-to-end workflow viable before refining each part (e.g., SD3 with DiT replacing the original text-to-image, followed by video diffusion and then 3D). It's hard to judge who will win.
Data has become the most important factor in model advancement. Clearly, OpenAI has the longest accumulation and highest quality of data. Stability still relies heavily on public datasets. Although they organized 700M images and videos for SVD, they still trail significantly behind OpenAI. For 3D models, the datasets used are also public (Unseen GSO and OmniObject3D), and the training volume isn't massive because high-quality videos of 360-degree object rotations are inherently limited.
In the 3D era, perhaps no single entity will be able to accumulate enough data alone. We will rely on communities like SketchFab. While this implies a longer timeline, it will result in high-quality, open-source resources once model breakthroughs occur—a truly "Beautiful World."
Considering the progress of various companies in the first three months of this year, we can conclude: hardware infrastructure is rapidly improving; language models have surpassed the passing grade and are driving industry applications; the Transformer architecture is moving into more modalities, pushing image, video, autonomous driving, robotics, and digital twin applications into accelerated growth; and while the "World Model" is still in its infancy and the path to AGI remains uncertain, it is no longer pitch black.
Perhaps the next three to five, or five to ten years, will bring another unprecedented upheaval. It will be a severe test for both the human physiology and spirit. Rather than how much the models will improve, I am more interested in how much potential we have left.