
Stability AI 发布 SV3D:单张图片生成 3D 信息的飞跃
Stability AI 新发了一个模型《Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion》,翻译为人话:输入单张图片,利用自家的视频生成模型,即可以生成物体的三维信息,或者准确一点讲,是不同空间视角看过去的投影图像。
由于这个模型的权重文件直接可下载,意味着能够本地运行,用于非商业用途,所以,我直接本地运行,用结果来解释模型的大概结构和想法。
1、模型本地试跑过程
1)我随便搜了一张企鹅的 png 图片,挑这张的原因很简单:主体清楚,透明背景,可爱。
2)从 hugging face 上下载权重文件:有两个分别是 sv3d_u 和 sv3d_p,每个文件分别为 9.36GB 和 9.37GB,比 svd(video diffusion)略小一点点,这很正常,sv3d 利用的就是 svd 模型。
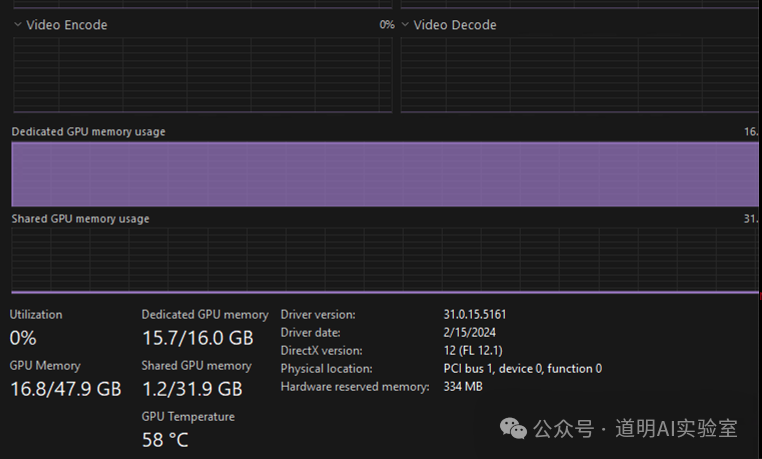
3)本地运行,当然需要 python 环境,支持 CUDA 的 PyTorch(python 版本只能是 3.10,pytorch 版本只能是 2.0.1,cuda 版本只能是 18.1,这边走了点弯路,换了不少版本,最终就在这些版本环境下可以跑下来),Transformers,然后一系列其他安装包。
运行时,模型加载到显存中,吃满了我试跑环境的 16GB 显存,还使用了一部分共享内存,导致生成速度变慢。
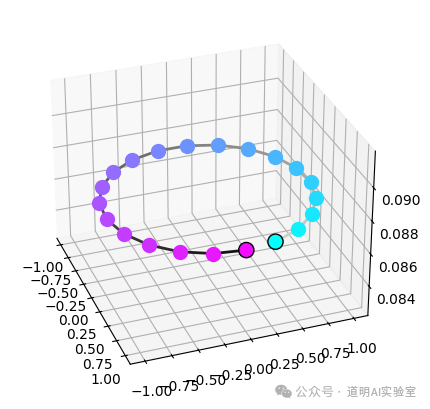
4)输入就是上面单张 png,输出是一系列不同视角的图,分辨率都是 576X576。
这边参数设定是 21 张。

如果更直观一点看的话,下图就是不同视角的空间位置。
5)以上其实就是 SV3D 模型的全部,但是为了检验效果,论文里还引入了三维重建的步骤,所以我也同样跑了一下。基本思想很简单:利用上面 21 张不同视角的图片来重建三维模型,然后旋转,出视频。这毕竟是一张照片输入,虽然有瑕疵,画面中下部灰色矩阵,但已经是巨大进步了。而且模型支持多图输入了,这就是为什么会有 sv3d_u 和 sv3d_p 两个模型,后缀 p 的模型是支持动态视角的,也就是通过多张图输入,得到更好的效果。

2、模型架构
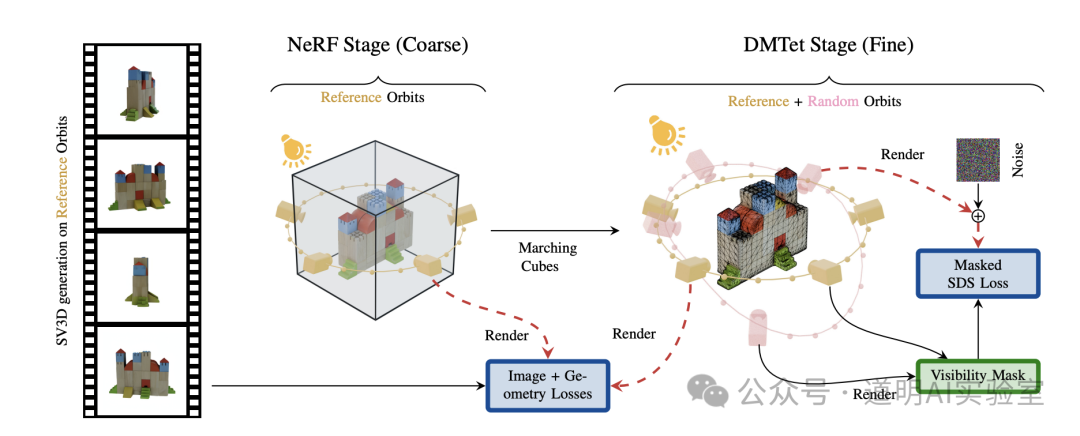
1)模型基本结构,就是下面这张图:利用到了 diffusion video 模型,训练数据是物体的三维模型旋转视频(分为静态轨道和动态轨道,看下方右图就能大概理解了);推理时,就是输入单张或者少数几张图片,输出图片物体的三维模型旋转视频,然后在旋转过程中“切片”,得到多角度的静态图片。
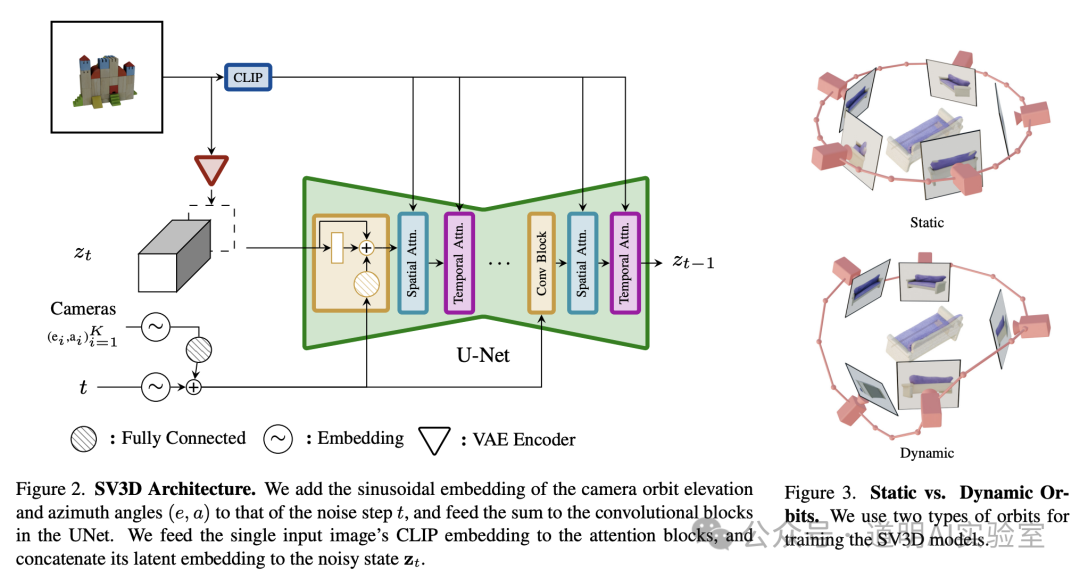
因为核心模型是 video diffusion,所以,还是用的基于卷积的 U-Net,而没有使用 sora 和自家 stable diffusion3 里的 DiT,diffusion transformer(后面肯定会用的,video diffusion 会升级到或许叫做 stable video diffusion transformer?)。生成的图像(视频)分辨率是 576X576,这个后面也会提升,但是如果到 1024X1024,模型规模也会显著提升。
2)将模型生成的不同视角图片,进行三维重建,用到两个模型,一个是 NeRF(英伟达的 Instant-NGP 版本),用于生成粗糙的三维模型,然后使用 DMTet 模型(同样是英伟达的),生成精度更高的三维模型。这部分不是 SV3D 的核心,只是作为验证。
3、结论
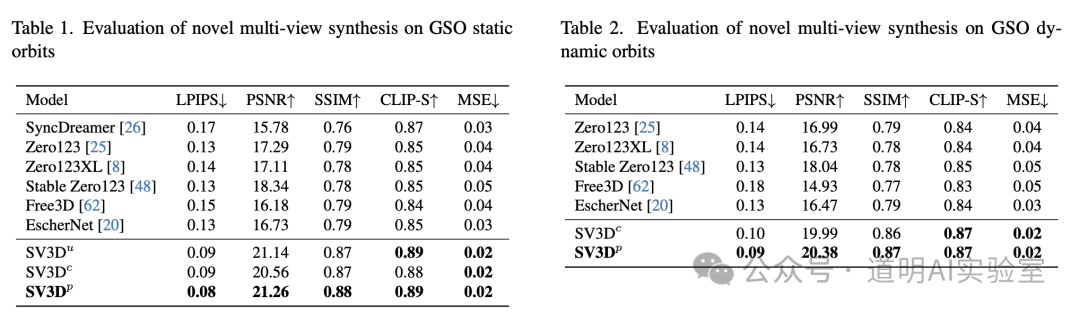
1)无论是评分结果还是我实测结果,确实是目前一张图生成 3D 的模型中最好的。

2)应用场景:这个模型已经可以快速应用到游戏设计和 AR/VR 应用开发中,576X576 的分辨率,稍加优化,就可以快速提供非常多的三维素材;
3)3D 生成进展速度,如果我们看完整的应用链条:文生图--->文生视频--->图(视频,文)生 3D,sora 完成了前面两步,大概对应到 2022 年底 ChatGPT 发布时的水平,或者再保守一点,往前推一年,介于 GPT2 与 GPT3 之间的水平。目前的 3D 模型,进展再晚个一到两年。也就是说,差不多 2-3 年之内,3D AIGC 达到“ChatGPT 时刻”。这一点都不慢,甚至可以说,跟 AR/VR 眼镜的成熟进度基本同步。
4)搞定 3D 的意义不仅仅是用在游戏娱乐,更是我认为的“世界模型”里下一个关键步骤,现在看来,sora 虽然是生成了视频,但是已经具备了非常高的空间一致性 ,我们是可以通过 SV3D 的思想,基于 sora 生成三维模型的,这个在之前的文章里我也讨论并演示过了。现在看起来,就是 OpenAI 和 Stability(我想背后一个重要原因或许是那已经部署好的 4000 个 Intel Gaudi2 GPU 集群)这两家在这方面的进展速度最快,不过他们的目标和路线略有一点点不同:sora 真的不是为了生成视频,stable diffusion 系列模型真的是为了生成图、生成视频、生成三维;sora 是一步把视频生成质量提到最高水平,stability 是先把终极流程跑通,然后再逐步完善(比如基于 DiT 的 SD3 替换原有的文生图,然后估计改进 Video Diffusion,然后再是 3D);谁快谁慢,目前不大好判断。
5)数据已经成为了决定模型进步的最重要因素。显然,OpenAI 的数据积累时间最长,质量最高,Stability 还必须大量依靠公开数据集,虽然在研究 SVD 模型时,已经整理了 700M 量级的图片和视频素材,但是相比 OpenAI 还是差距很大。进入到 3D 模型,用的数据集也是公开的(unseen GSO 和 omniObject3D),训练量也不是很大,毕竟这种完整的绕物体旋转一圈的视频素材量本就有限。
6)进入到 3D 时代,或许单一主体都没有足够能力积累足够的数据,只能靠类似于 SketchFab 这样的社区,这虽然意味着更长的时间,但也会带来未来一旦模型突破后更优质的开源可用资源,这才是“美丽世界”。
7)如果结合今年到现在为止三个月不到,各家的进展,我们大概可以得出这样的结论:硬件基础设施快速完善,虽然算力无止尽,但是相比去年此时,已不可同日而语;语言模型已经全面超越及格分,正在驱动各行业应用快速落地;transformer 架构进入更多模态,推动图像视频模型进步,推动智能驾驶、机器人、数字孪生等应用进入加速发展期;“世界模型”初见雏形,通向 AGI 之路依然充满不确定性,但是已经不再是一片漆黑。
也许,就是接下来的三年到五年,或者五年到十年,又是一次前所未有的剧变,只是对人的生理与精神都是更加严酷的考验,相比模型能进步多少这个问题,我可能对我们的潜力还有多少,更感兴趣。