After a few days of waiting, although I didn't receive an official confirmation email from Google, the "Gemini 1.5 Pro" option appeared under the models in my "Google AI Studio" platform. This means I can finally start experimenting with the "magic" of a 1-million-token context.
I tested three questions, all of which were previously unimaginable.
Question 1: Upload a TV episode and generate a plot summary.
This is likely the first large model capable of handling a video over an hour long. To leave some buffer, I only uploaded the second episode of the first season of Person of Interest (in the AI era, this classic show is still worth re-watching). The duration was slightly over 45 minutes.
I asked only one question: generate a story summary. See the screenshot below.
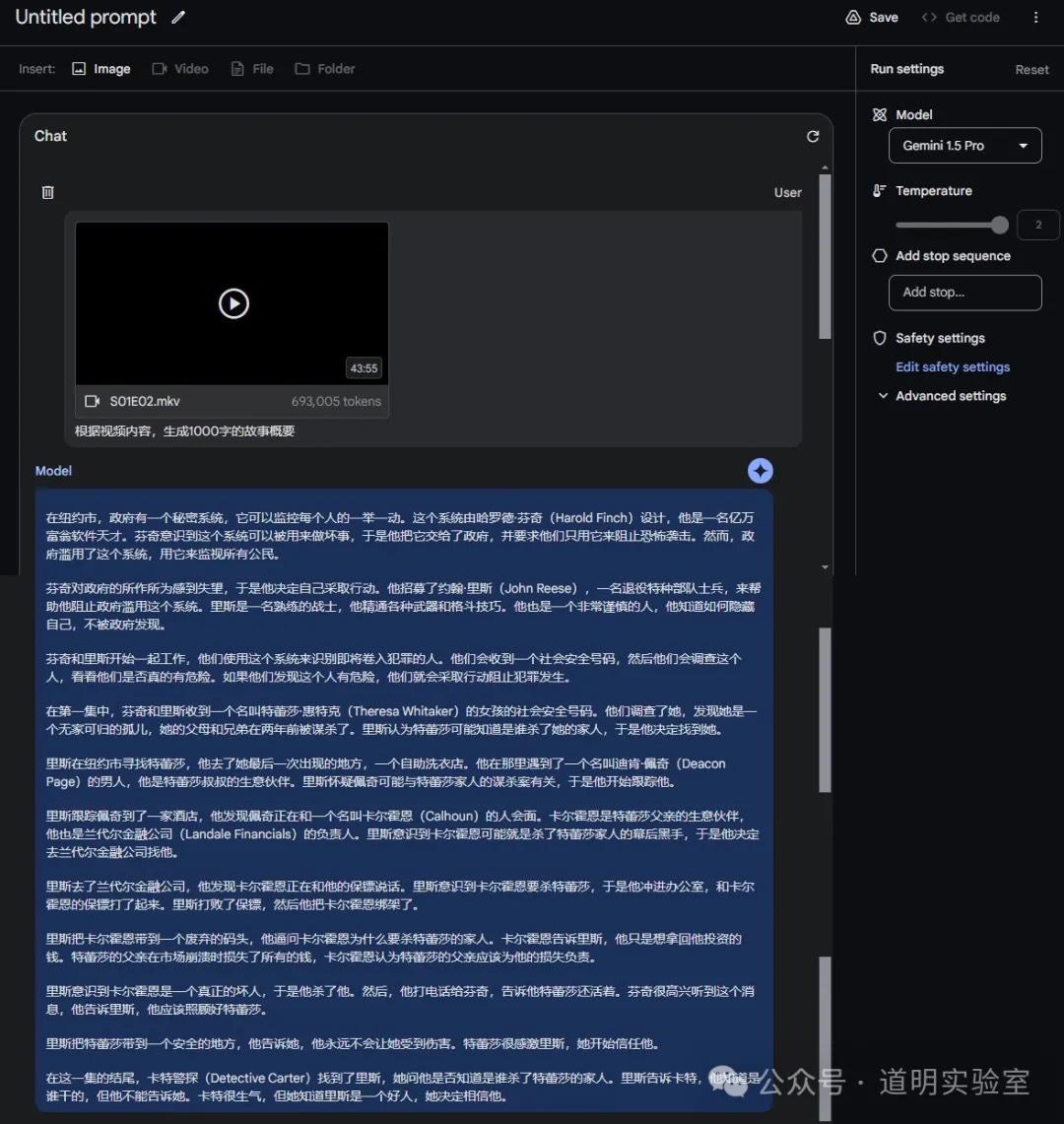
First, a TV episode of under 44 minutes equates to a token size of less than 700,000.
Second, the story summary was almost entirely correct. Although the video had subtitles, being able to understand the story to this level suggests that we might no longer need those "watch a whole movie in five minutes" summary videos.
Using "magic to fight magic" so that humans can return to more meaningful tasks is my wish, and I firmly believe it will happen.
Question 2: Upload 19 papers and extract a knowledge graph.
This is the first model to natively support a million-token context. Beyond long videos, its best use case is processing a batch of documents to build a cross-document knowledge graph. I uploaded 19 research papers related to image and video generation and asked to extract 100 keywords and generate a knowledge graph.
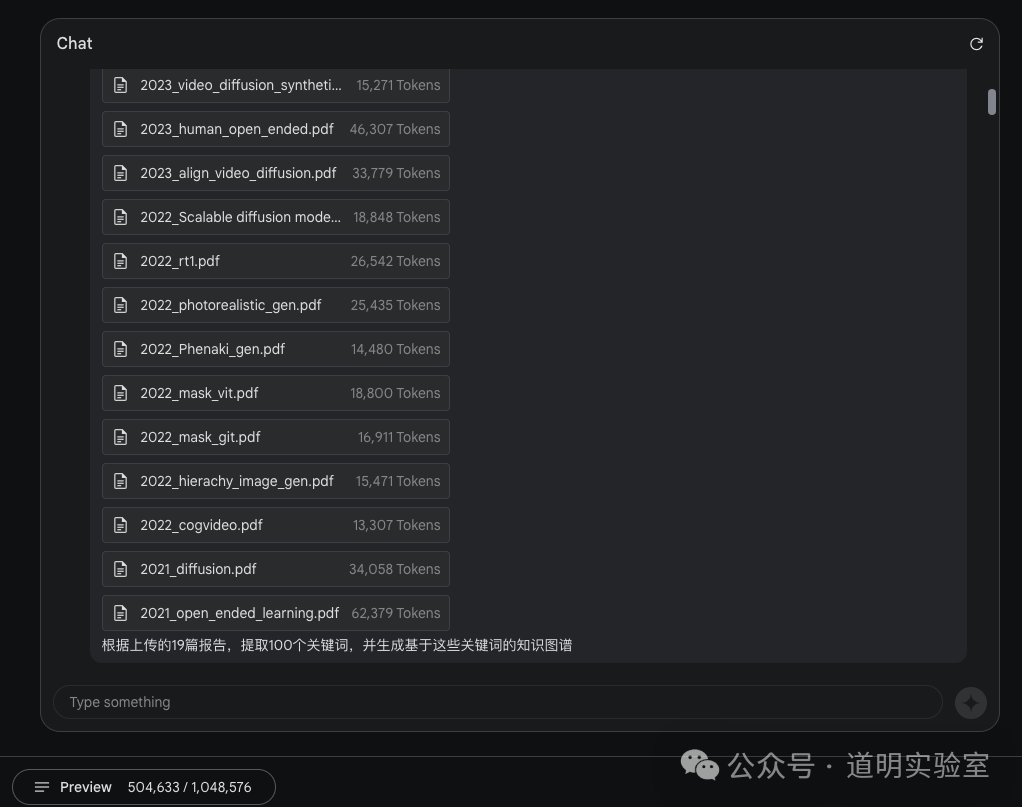
These 19 papers occupied about 500,000 tokens, which is equivalent to feeding the model 500k * 0.75 words at once for analysis.
The result is as follows:
Knowledge Graph based on 100 Keywords and 19 AI Research Reports:
Based on the 100 keywords and the content of the 19 research reports, I have created a more detailed knowledge graph that captures the relationships between these concepts. Please note that this is still a high-level overview, and the actual knowledge graph could be even more complex with additional nodes and edges to represent more nuanced relationships.
Nodes:
- Model Types:
- Diffusion Models: Latent Diffusion Models (LDMs), Denoising Diffusion Probabilistic Models (DDPMs), Cascaded Diffusion Models, Score-based Generative Models (SGMs)
- Autoregressive Models (ARMs): Transformer-based ARMs (e.g., DALL-E, CogVideo, Parti)
- Generative Adversarial Networks (GANs): StyleGAN, Long Video GAN (LVG)
- Other Models: Variational Autoencoders (VAEs), Flow-based Models, VQ-VAE, VQGAN, Masked Autoencoders, MaskGIT, C-ViViT
- Applications:
- Image Generation: Text-to-Image Generation, Class-Conditional Image Generation, Unconditional Image Generation, Image Inpainting, Image Outpainting, Image Extrapolation, Image Manipulation, Super-Resolution, Layout-to-Image Synthesis
- Video Generation: Text-to-Video Generation, Image-to-Video Generation, Video Prediction, Frame Interpolation, Multi-view Generation, Novel View Synthesis, Personalized Video Generation, Visual Storytelling
- Robotics: Robotic Control, Planning, Autonomous Driving Simulation
- Datasets:
- Image Datasets: ImageNet, Places2, MS-COCO, LAION-5B, JFT-300M
- Video Datasets: Kinetics, BAIR Robot Pushing, Moments in Time (MiT), WebVid-10M
- Technical Details:
- Attention Mechanisms: Self-Attention, Multi-Head Attention, Cross-Attention, Window Attention, Spatial Window (SW), Spatiotemporal Window (STW), Causal Attention, Bidirectional Attention
- Other Techniques: Mask Scheduling Function, Iterative Decoding, Conditioning Augmentation, Classifier-free Guidance, Gradient Checkpointing, Positional Encoding, Sinusoidal Embedding, Layer Normalization, Adaptive Layer Norm (adaLN), adaLN-Zero, ResNet, EfficientNet, TokenLearner, Universal Sentence Encoder (USE), FiLM, VQ Objective, Commitment Loss, L2 Loss, Perceptual Loss (LIP), Video Perceptual Loss (LVP), Adversarial Loss (LAdv), StyleGAN, Cross-Entropy Loss, Causal Masking, Decomposed Action Space, PopArt Normalization, Multi-task Learning, Multi-Agent Learning, Fictitious Self-Play, Self Reward-Play, Exploration Distillation Loss, Principal Component Analysis (PCA), Spherical Interpolation, Text Diffs, Kohonen Network, Self-Organizing Maps
- Metrics:
- Image Quality: Fréchet Inception Distance (FID), Inception Score (IS), Precision, Recall, Classification Accuracy Score (CAS)
- Video Quality: Fréchet Video Distance (FVD)
- Other Metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS)
Edges:
- Model Type - Application:
- Diffusion Models can be used for Text-to-Image Generation, Image-to-Image Translation, etc.
- LDMs can be used for High-Resolution Image Synthesis, Text-to-Video Generation, etc.
- ARMs can be used for Text-to-Image Generation, Text-to-Video Generation, etc.
- GANs can be used for Unconditional Image Generation, Video Generation, etc.
- Model Type - Technical Detail:
- MaskGIT uses Bidirectional Transformers and Masked Visual Modeling.
- C-ViViT uses Causal Attention and Vector Quantization.
- LDMs use Denoising Autoencoders and operate in Latent Space.
- Application - Dataset:
- Text-to-Image Generation is evaluated on MS-COCO.
- Video Prediction is evaluated on BAIR Robot Pushing and Kinetics.
- Model Type - Metric:
- FID is used to evaluate the quality of Diffusion Models and ARMs.
- FVD is used to evaluate the quality of Video Generation models.
First, the extracted keywords indeed covered the 19 uploaded papers and provided nearly accurate classifications.
Second, while it generated some knowledge graph relationships, the quantity and complexity haven't yet reached my expectations. Granted, this is in the testing phase rather than production; the product team still has much optimization to do. Even so, these results sufficiently prove the capability of the million-token context.
Question 3: Upload a long document and ask questions.
I uploaded Microsoft's research paper "The Dawn of LMMs" published during the GPT-4 multi-modal release. It is 166 pages long with a file size close to 50MB (Claude 3 Opus supports a max single file size of 10MB). After uploading, it consumed about 100,000 tokens.

My first specific question came from section 9.7 of the original text.

The answer was as follows:
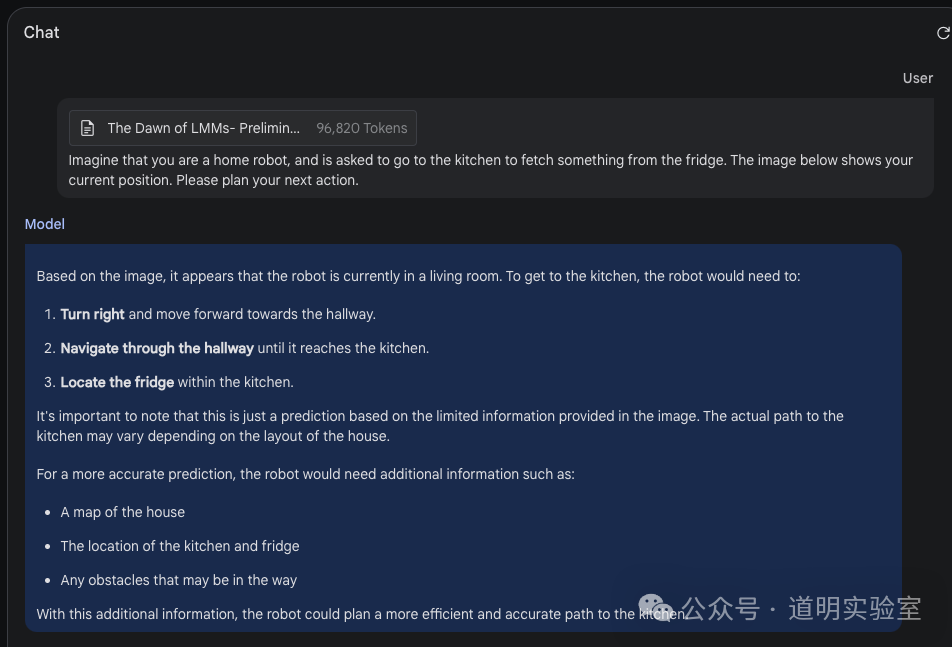
It not only precisely located the original text but also regenerated content based on GPT-4V's responses, showing that Gemini 1.5 fully understood the question.
After locating details, I tested its summarization ability.
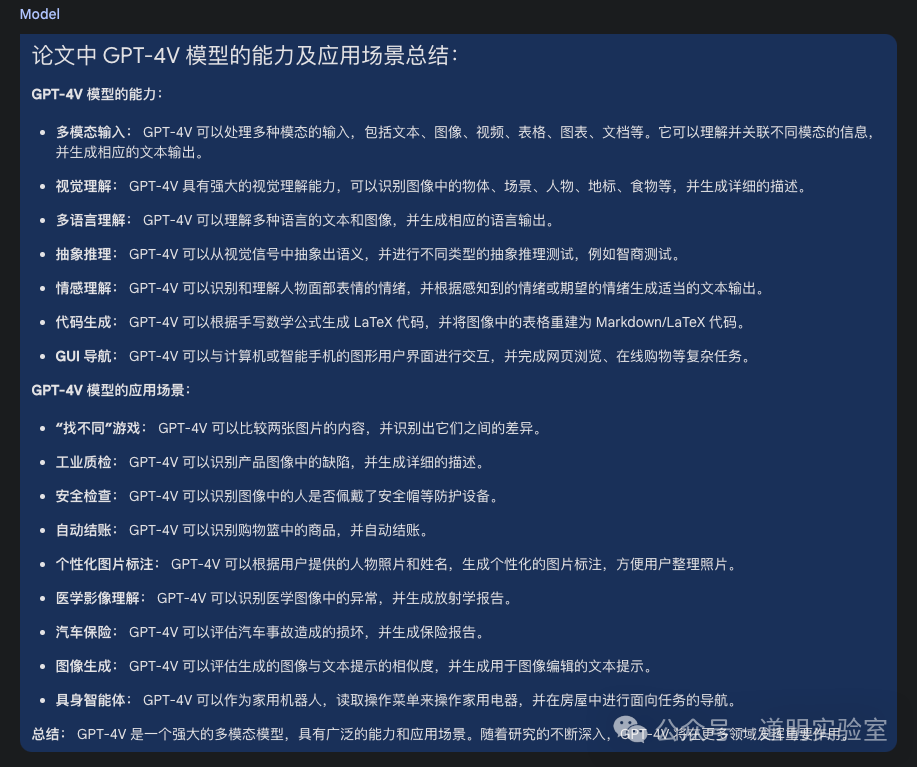
It was nothing but complete and accurate. Although Gemini 1.5 needs more time for optimization before commercial use, I am already eager to integrate the model into personal applications for non-sensitive data. With Sora, Claude 3, Gemini 1.5, and other anticipated models on the way, the certainty of AI entering full production in 2024 is becoming higher.
Bonus: Analyzing LeCun's latest interview video.
Yann LeCun's interview video has been viral lately. I previously had Gemini 1.0 Ultra "watch" it and provide a summary. Frankly, while that feature was unique, it had many limitations:
- It only worked with YouTube links.
- The model actually analyzed the text transcript attached to the video's webpage.
Furthermore, for the first question involving the TV episode, the video had subtitles. Thus, for that question, we couldn't be 100% sure if the model was actually "watching" the show or just "reading" the subtitles (the difference being understanding characters, plot, and dialogue by audio).
So, I created a "bonus" test: I recorded LeCun's interview video, which had no real-time subtitles, and considering copyright and processing, I cropped a half-hour segment.
The video essentially looked like this: just expressions and voice, no subtitles. The half-hour video was about 480,000 tokens. Considering the previous 45-minute TV show was about 700,000 tokens, it is safe to assume token length is proportional to video duration and independent of resolution (the TV show was 1080P, while this interview was compressed to 480P).

After uploading, I asked two simple questions. The first was to generate a detailed summary. The answer:
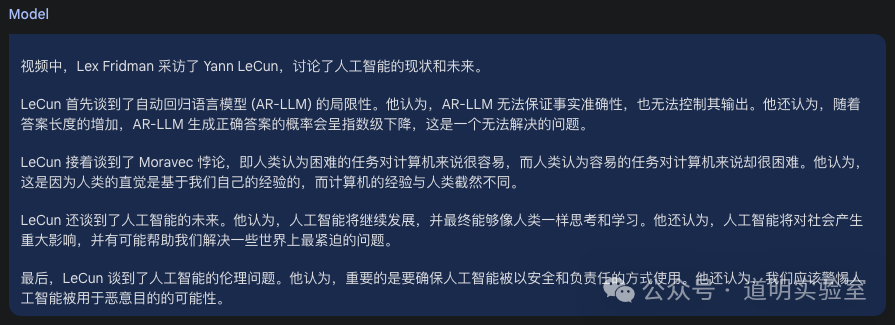
Though not long, the points were accurate.
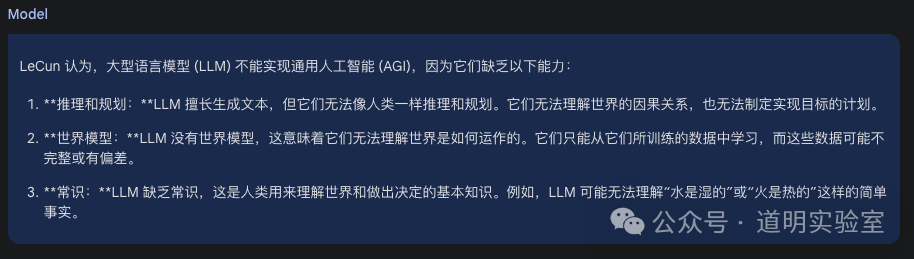
The second question was more specific: Why does LeCun believe LLMs cannot achieve AGI?
Undoubtedly, this is the first large model that "understands" sound (some papers introduce multi-modality with sound understanding, but only in descriptions; while ChatGPT accepts voice input, it uses an embedded Whisper model, essentially a voice-to-text input method).
As for the answer, it was clearly correct.
If we follow LeCun's definition, Gemini 1.5 cannot yet be called a World Model, but it is clearly the closest one among current models, far surpassing Sora in this regard: Sora is a generator, right? Sora doesn't understand sound, right? Sora lacks conversational ability, right?...
Of course, if OpenAI integrates Sora's functions into the next version of GPT (be it 5 or 4.5) and adds audio capabilities, it could certainly compete with Gemini 1.5 across the board.
But for now, there is only one unique model called Gemini 1.5.