
ByteDance has released a paper detailing the construction of a single cluster with over 10,000 GPUs (12,288), achieving a computing utilization rate (MFU) of over 55%.
Architecturally, the network is still based on the Clos "Fat-Tree" structure. One key improvement is the separation of uplink and downlink paths on the top-level switches, which effectively reduces collision rates.
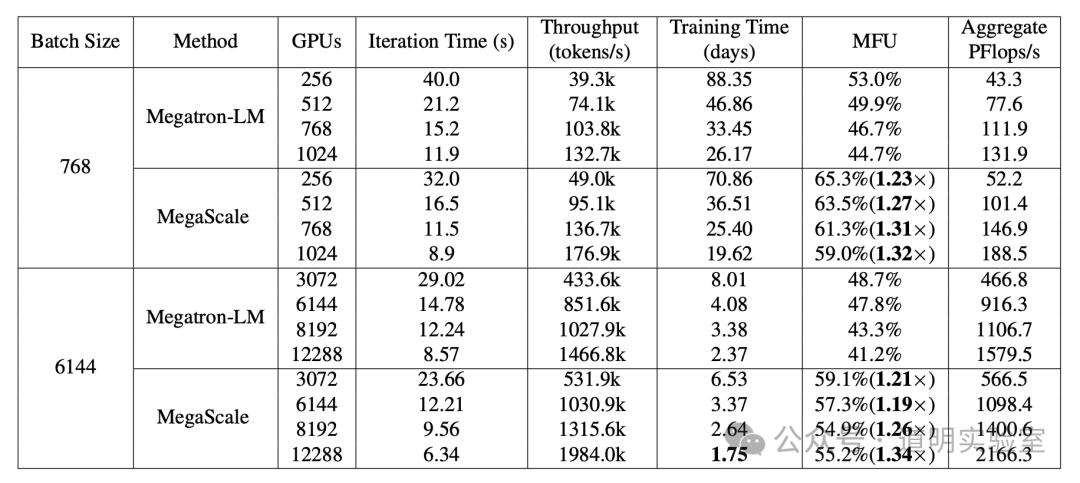
This is likely the best paper from a domestic Chinese company I have read in a long time:
It is highly objective, detailed, practical, honest, and confident.
I recommend that anyone interested in AI training clusters read it carefully.
Since this is a short review, I will skip over technical deployment details. I also won't cover the ratio of GPUs to optical modules; for domestic companies restricted by chip availability, the network simply needs to match the hardware. High Model Flops Utilization (MFU) doesn't necessarily mean high total computing power. While this cluster is among the highest in scale, its performance isn't at the absolute top tier due to hardware constraints.
The real focus lies in the problems encountered when a cluster exceeds 10,000 cards and ByteDance's solutions. If this paper is accurate (which is highly likely), we should have sufficient confidence in the upcoming significant leap in the capabilities of domestic models.
Drastically Optimized Initialization Time: Without optimization, the initialization time for a 2,048-GPU cluster was 1,047 seconds. After various optimizations, this dropped to under 5 seconds. For a 10,000-GPU cluster, initialization time was reduced to under 30 seconds.
Rapid Recovery After Errors: The paper refers to this as "Fault Tolerance," though I find that term slightly inaccurate. As the paper states, software and hardware failures are inevitable and frequent in a 10,000-card cluster, causing training to stop and restart. The first layer of defense is Checkpointing—frequently saving the training progress so that after a crash, the system can quickly reload the last save and resume. The paper introduces file system optimizations to speed up these frequent read/write operations. The aforementioned reduction in initialization time is crucial here, as restarts are common. The third layer is a comprehensive system monitoring and automatic detection mechanism, which can automatically detect, locate, and recover from over 90% of faults.
Hardware Specs: As of September 2023, ByteDance had established a cluster of over 10,000 Ampere architecture GPUs (A100 and A800) and is currently building clusters based on the Hopper architecture (H100 and H800).
"Lessons Learned the Hard Way": Issues like the "personality" of specific GPUs (some cards are just slower or quirkier than others), network flickers, and unnecessary wait times are discussed. You cannot gain insights into these problems without consistently managing clusters of hundreds or thousands of nodes. Therefore, large-scale model training is essentially an engineering problem.
Conclusion: Clearly, ByteDance spent nearly a year "solving" the infrastructure. This is perhaps the most critical step in the model development lifecycle.