
有必要用最短的篇幅,把过去一周一些发布了,却有点生不逢时,碰上sora刷屏的“新模型”做一下拾遗。
通向AGI的道路充满不确定性,每一个头部玩家的想法其实都很重要,也许某一个模型的表现不一定很吸睛,但是里面或多或少总会存在不少闪光点,如我昨天文章里所言:证实一些设想,否定一些设想,提出一些新设想……
所以,第一个,来自Meta的V-JEPA,发布于2月15日。
1、这不是一个生成式模型,而是预测视频缺失的部分或者被遮住的部分。全称是Video Joint Embedding Predictive Architectures;
2、预训练使用未打标签的视频数据;
3、模型的目标是希望可以像婴儿一样逐渐从内在学习并理解物理世界的概念,一个直观的效果是模型可以理解到“把什么东西撕成两半”;
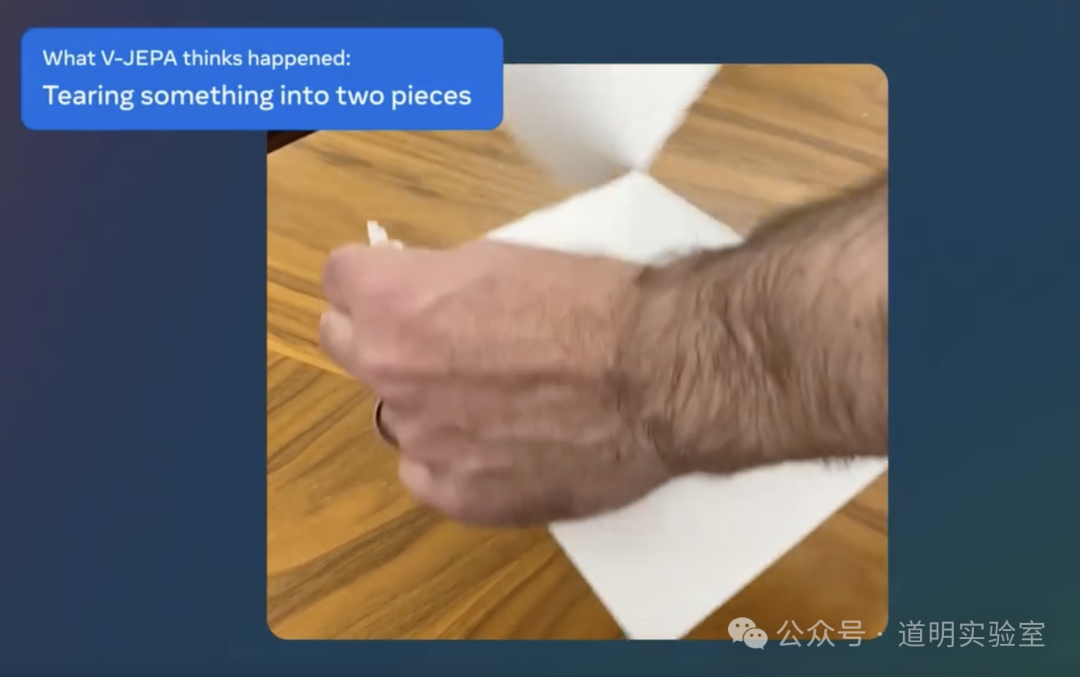
4、模型开源,包括训练代码,模型在“VideoMix2M”数据集上训练,但是时间仓促,我还没找到这个数据集,所以不确定是否是公开可用的。
5、初步结论:这个模型显然是实验性质的,用来验证一些关于AI推理及规划能力的设想;最大模型参数也就6.3亿,而且暂时无法验证是否可以scaling(模型表现随着规模提升而提升),初步感觉应该是可以的;
6、我有一个“脑洞”:依靠Meta自己的图像分割算法把视频里的图像进行分割,随机masking(遮盖),自监督学习,是不是很像我们学生时代的自己刷题自己对答案,然后就“熟能生巧”了的感觉?
第二个模型,Stability AI的Stable Cascade。
1、效果超过Stable Diffusion XL (Turbo),推理速度更快。
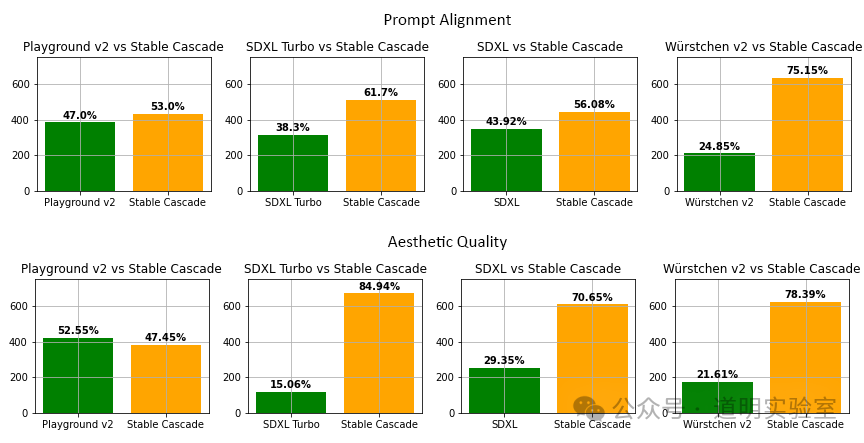
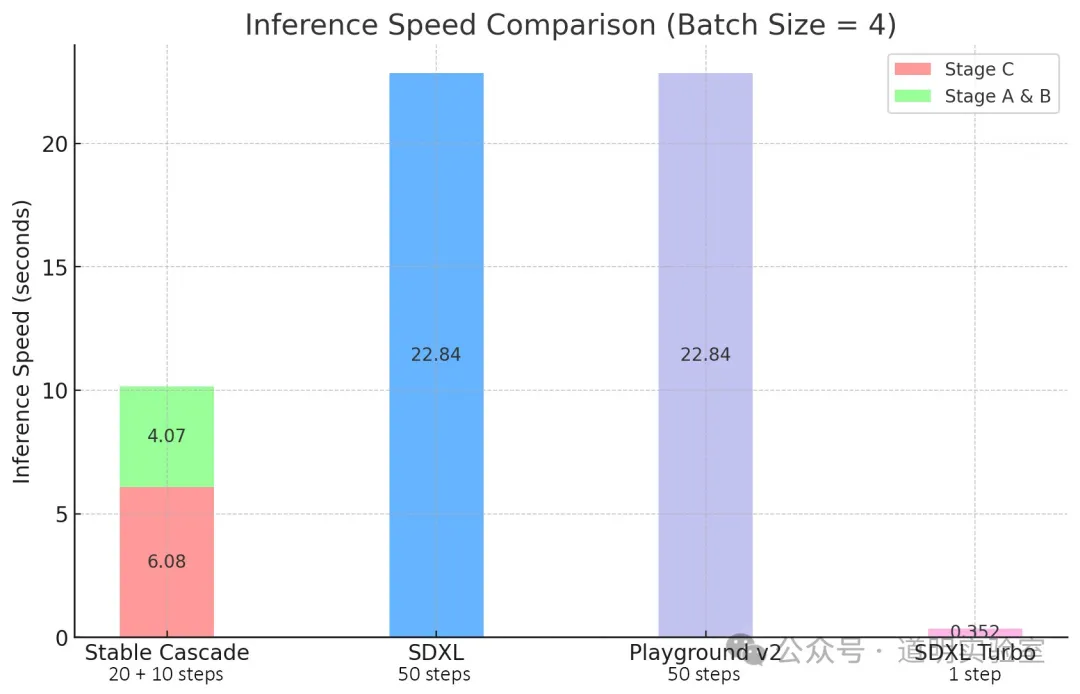
2、使用“Würstchen”架构,因为可以用更小的latent空间,所以推理速度更快,效果还更好。
3、开源,不是模型参数开源,是训练、精调等,都开源。
4、卷。
第三个模型,Cohere的Aya,多模态,开源。
1、“超过”目前所有的开源多模态模型。
2、来自全球超过3000名独立研究人员共同研发。
3、看起来有非常详细的数据及模型介绍文档,很适合静下心来精读。
第四个模型,Amazon的BASE-TTS。
十亿参数的语音合成模型,训练数据有10万小时。声称出现了“涌现”。
总结
AI研究才是目前最卷的领域。我本来以为要到三四月份,各家才会开始拿出里程碑式的新进展,没想到,现在就开始了,AI研发似乎在从脉冲式的离散序列变成连续曲线。
但是,很明显,越来越看不到名不见经传的公司突然拿出一个模型。如果说2023年是预赛的话,2024年至少是进入到了半决赛,此刻还没亮过相的公司,应该算是出局了。半决赛还要淘汰多少?估计是绝大多数吧。
闭源和开源模型逐渐形成了各自的闭环,闭源模型披露的信息越来越少,虽然能力依然显著高出一筹,但是开源模型的可用性也在快速的提升。少数几个巨头,剩下的都是小作坊或者说,类似Cohere表述的“独立研究人员”。
因为,从根上说,AI的商业逻辑不就是成本最小化嘛?“独立研究人员”是很自洽的。