
最近,个人对于搜索的行为发生了一些变化:越来越多的搜索还是回到了Google,虽然“八卦”,“查单词”等还是会在Perplexity之中。
不知道怎么了,Perplexity的质量下降速度达到了惊人的可明显感知的程度,与之相比,加入“AI Overview”的Google搜索体验却有了显著提升。模型还是最重要的,不仅仅是模型能力,而是能力和成本的综合。
搜索是我在去年底做前瞻时,认为今年会是需求大爆发的第一个AI应用领域。事实确实如此。但我观点的基础不是建立在“人使用”之上,而是建立在“AI自动调用”之上:前者的天花板大概就是目前20亿不到的Google日均搜索量的若干倍(两三倍?);而后者,可以是无上限,极限情况下,AI可以为每个人每天都进行许多次的信息检索,再总结,最后压缩到很简单的一幅infographic图,一页纸,甚至就是一段语音,当然,也可以是一段短视频。
所以,天花板无上限,就要满足两个要求,我总结为“迭代”与“压缩”,迭代就是给模型一个初始任务,它可以自己不断的演进下去,无论是不断的步进搜索,穷尽信息,还是不断的尝试,穷尽可能性。只要算力足够,它可以一直执行到所有结果都收敛为止。
显然,理论上,AI编程也符合上面两个要求。
很多人会说Agent,说过很多遍,Agent的实质就是编程和搜索,当然也包括其它模态(声音,图片,视频)的生成。
简单而言,在AI还需要人这个物种的时候,它的目标是“给人看结果”,它的方式是“计算”。
在token替代流量,成为AI时代最重要的基础指标时,迭代量决定了token量,压缩率(处理的token量比上人接收结果的处理时间,比如几秒钟看一张图,一分钟看多少字,比如,一分钟的视频)决定了天花板倍数。
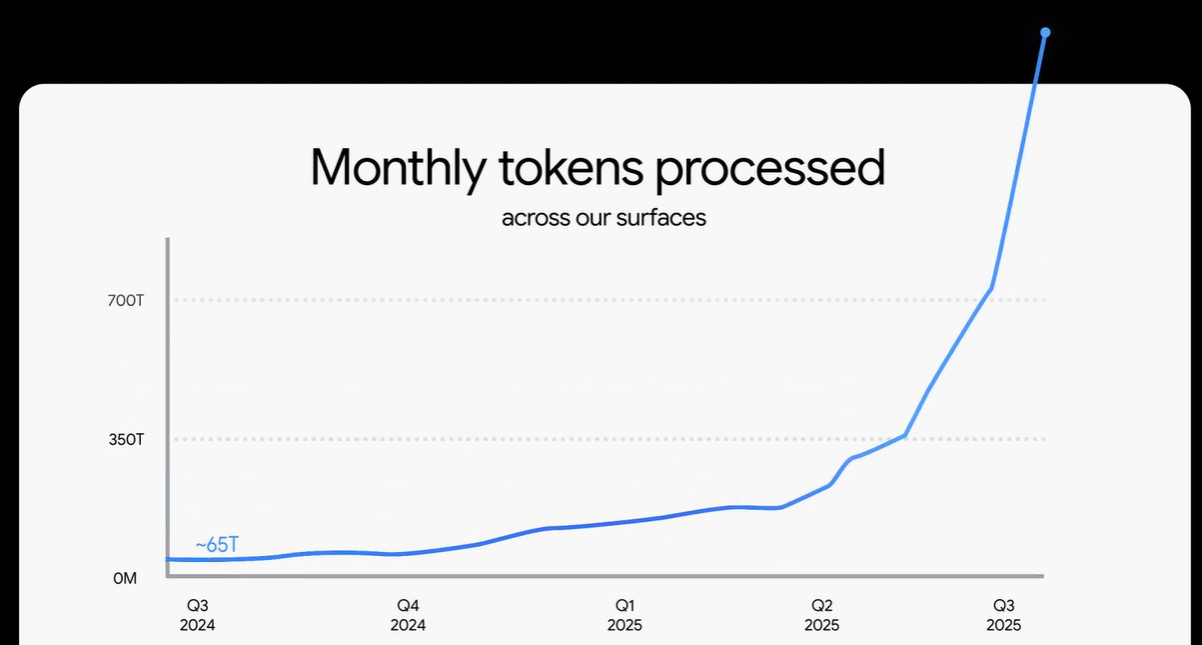
仅靠搜索和AI Coding(其实主要是搜索),Gemin“画出”了一个token用量指数级上升的曲线。仅靠AI编码,Anthropic(Claude模型母公司)每个月都在提高全年ARR预期,甚至最近给出了26年200-260亿美金ARR的“饼”。
以上是今天要探讨的两个内容的铺垫:1. 第一个内容是谁将扛起下一个token用量大爆发的大旗?2. 理论上,即使不需要新的模态,如上所述,仅搜索和coding,都还有无限的空间,那么现实大概是怎样的?
对于第一个内容,很多人包括我都把目光放到了多模态,尤其是sora2发布之后,让很多人看到了AI视频的巨大潜力。
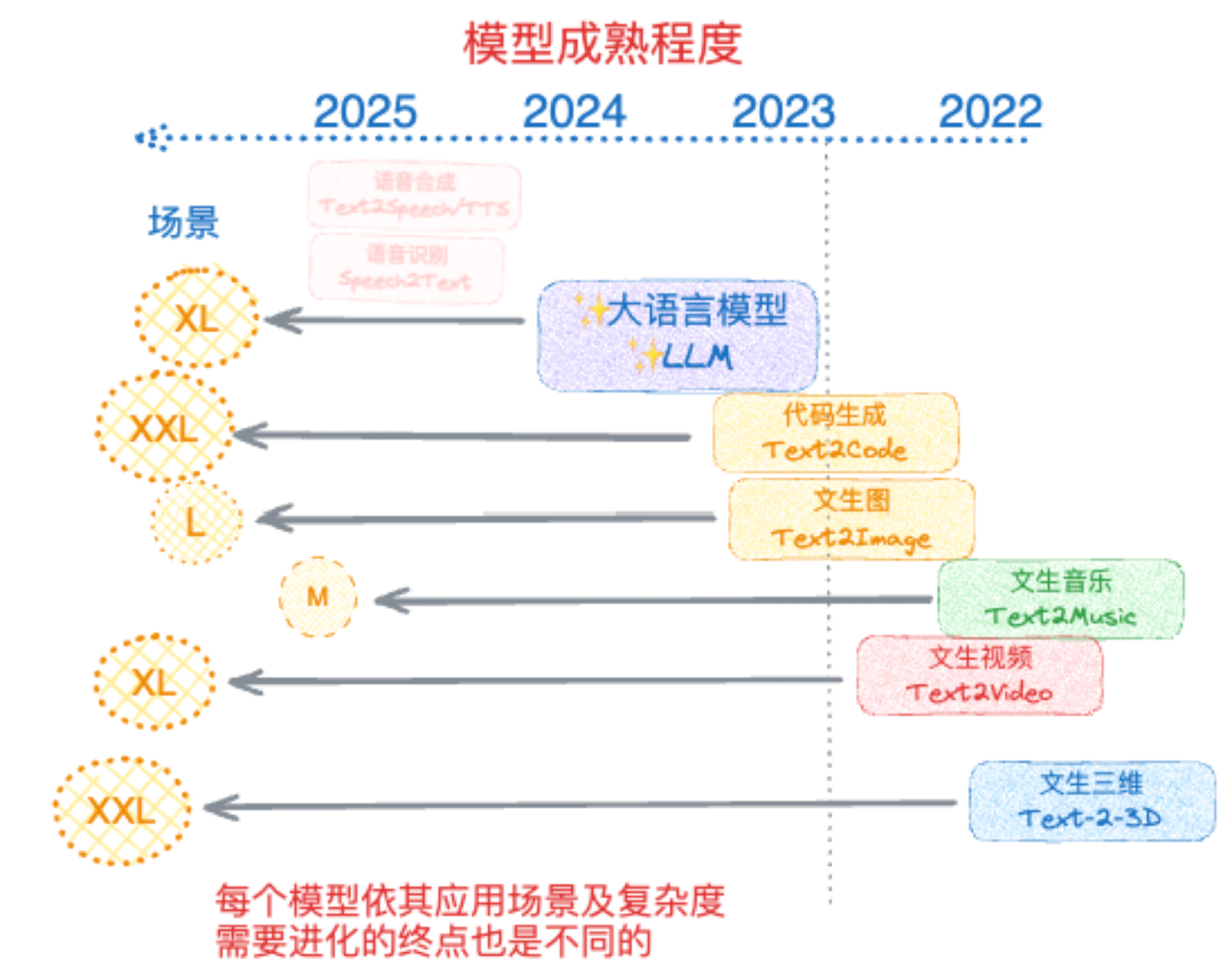
上面这张图是我在23年底画的:竖条虚线代表22年底“ChatGPT时刻”,或者说“GPT-3.5”时刻。不同模态的位置代表在当时(23年下半年)相对于“GPT-3.5”时刻所处的位置,比如,大语言模型显然进步了,毕竟GPT-4出现了,文生图和代码生成确实可以使用了;左边的椭圆形圈代表场景潜在的市场大小对比(定性)。
当然,当时用了那个时间点的语言体系,因为模型大家都喜欢统称为“文生XX”,意思是通过一段文字来生成,也对,也不对。
当时,把搜索归到了LLM之中,实际上就是一个LLM对搜索工具的调用和结果处理。同样,也对,也不对。
如今来看,代码能力显然早就跨越了“GPT-3.5”时刻,GPT-4o的生图模型开始,也就算跨越了,如今nano-banana更是再进一步,sora2应该也算至少到达了。
所以,这些模态,确实有“爆发”的潜力。
但其实,考虑两个方面,也许图片和视频并非如我们设想的那样可以达到甚至超过如今AI搜索 and AI Coding的token用量。
一是,目前的量,我在上一篇文章里曾经计算过图片和视频的token量,当然依照Google的数据。
这里直接说一下结论:Google云公布至今处理了130亿张图片,2.3亿个视频(我们按照8s计算),这些图片的总token量是20T,视频的量大概是一半。这还是至今为止总的处理量,但即使这样,相对于Gemini一个月的1.3Q的token量,差不多只是3%水平。
当然,很多观点可以说,这才开始,未来空间巨大。可是如果我们回到前面说的天花板测算的两个要求的第二点,压缩率来讨论的话,也许判断会有不同。
首先,我们为什么要出图片,视频,就是为了给“人”看的(又有人会不同意,训练自动驾驶和机器人不是要生成很多图片和视频吗?有时候写文章比较麻烦的点就是在这里,需要不断去填“逻辑漏洞”,试想,为什么要给“机器人”看图看视频,不也是因为人看的吗,还有,即使训练的模型再多,跟全球八十亿人比,量级根本不能比的)。仅仅这一点,就有巨大的差异了。
其次,虽然可以说为了生成图片,视频,还是需要处理很多信息,但最终就会限制在图片和视频作为人机界面的这个载体之上了,还会面临“真人世界”的剧烈惯性竞争。即使在AI生成之前的社交媒体,我们也会承认内容太多,信息过载,而不是信息不够。
我贴一张Gemini的Deep Research结果的图,如下:
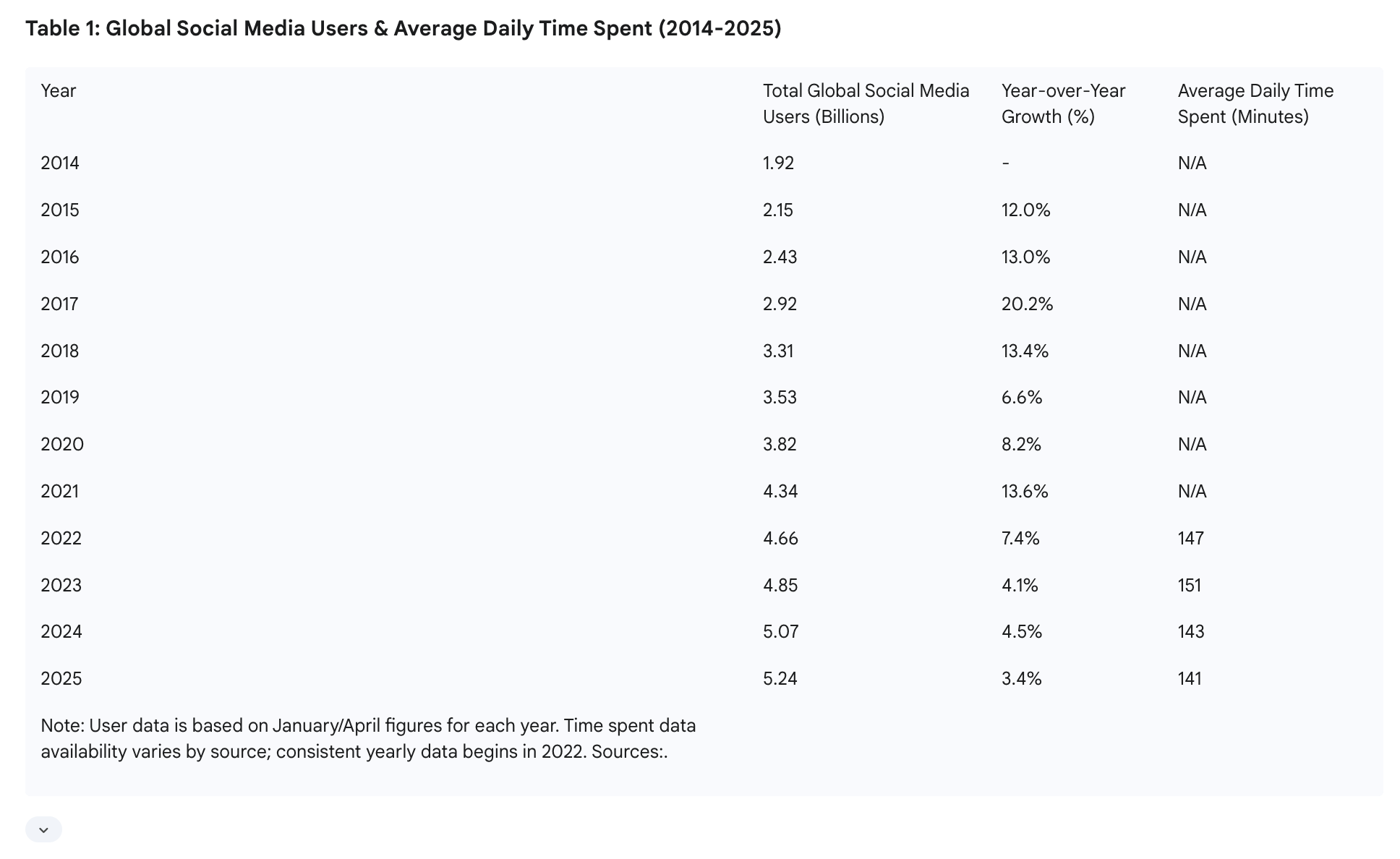
所有社交媒体用户和平均时长。如果我们把141分钟换算成秒,再乘以人数,就是44.3T秒,假设全部模态就是视频,那么这个44.3T就是每天全网络的视频观看总秒数,每秒视频大约15k的token量。所以总观看是不到700Q的token,但是观看不代表生成。
来自 https://influencermarketinghub.com/how-much-content-does-tiktok-generate-in-just-one-day-study/ 的一份数据,tiktok视频的平均观看数是2500。如果我们再假设,长视频短视频加起来平均时长是15S,上面的计算结果成为17.7T的tokens。对于这个结果,我依然更倾向于高估了,但是我们就假设本身就还会有增长空间。
那么,把社交媒体(人的注意力)的内容全部假设成为通过AI生成的视频,考虑增长,大概的一个天花板数量是20T的token每天,一个月600T,还不到Gemini上个月的token量的一半。
当然,我们还可以有一系列挑战以上结论的点:为什么要发视频到社交媒体,自己生成视频给自己看不行吗?当然可以,怎么都可以。
还可以说,视频可以取代好莱坞电影。恰好,我让Gemini做了电影票房的数据研究。
还有跟流媒体比较的。不深入探讨了,有兴趣的可以自己分析。
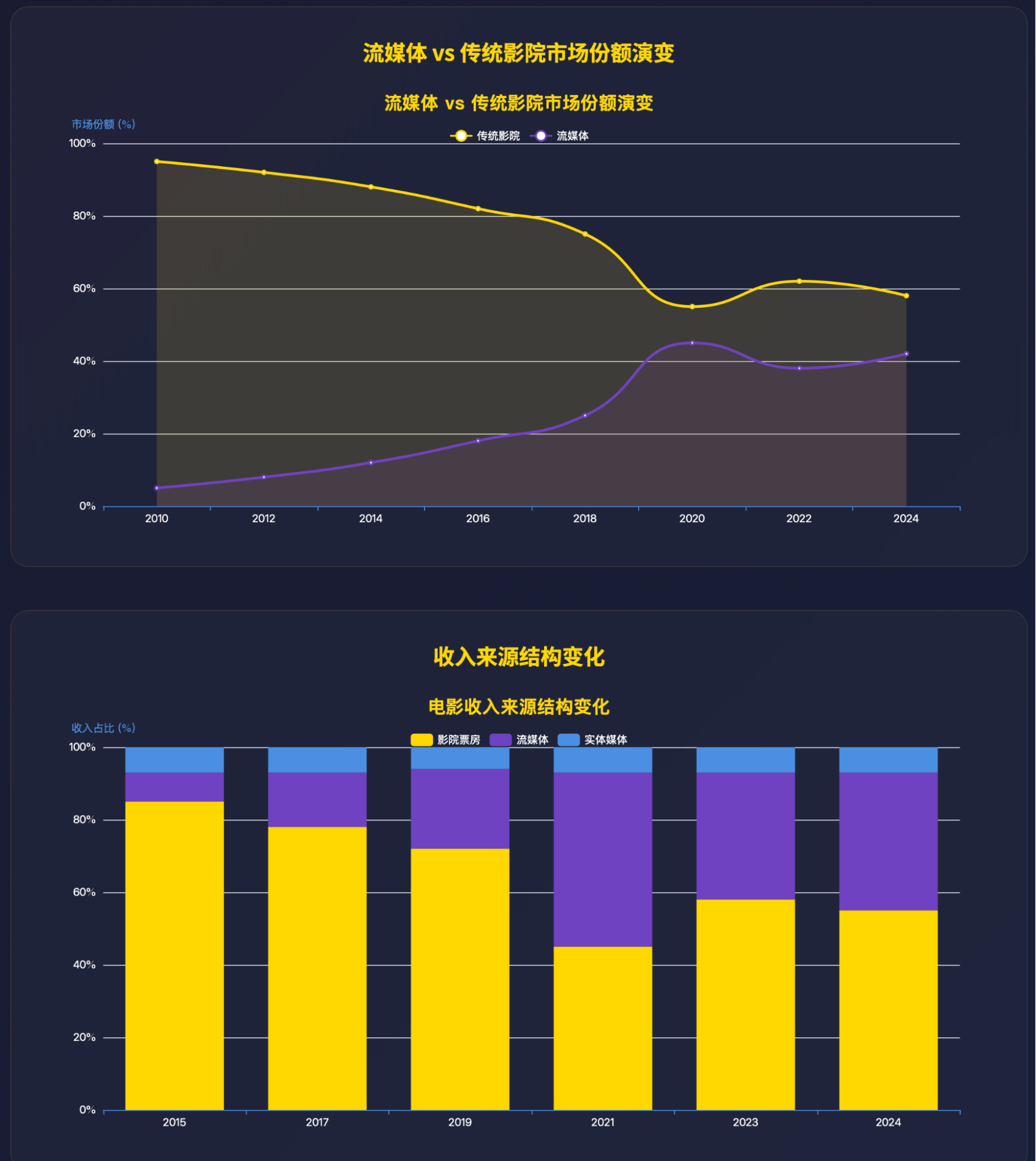
当然,我们还可以质疑上面这些Gemini深度研究的数据是“错”的,是“幻觉”,那就需要进入我今天第二个讨论内容了,稍等。
综上,我不认为在可见的两三年内,图片和视频可以成为杀token的最大主力军。就是因为,它们作为人机交互的界面,受到人的物理约束。
那么,还有一个交互界面,语音呢?有意思的是,我反而认为这可能会是容易被忽略的部分,但因为总量算起来可能还是超不过视频,所以只是单纯因为很多人对它的想象空间偏小,反而会超预期:一个人是可以长时间一直跟AI共同工作或者聊天的,语言是一个比文字效率高5-10倍的模态,这意味着语音的使用时长上限是挺高的。但在真正很好落地前,还是有几个痛点:一还是输出效率问题,即在语音模式下,AI应该如何综合语言,文字,图片,视频的回复模态,真正提高人机沟通效率;二是环境适配度,目前的语音模型在安静的单人环境下表现都不错,但是一旦人多,或者背景噪音比较大时,就不可用了,这不是模型本身问题,而是音频处理软硬件需要共同解决的问题。
当然,还有个模态,3D,显然,还太早。
实际上,为什么要提出上面的问题,即新模态“杀token”的能力,而不是假设AI搜索和coding还可以继续保持动能,拉动token用量的持续环比高增,就是第二个问题要讨论的了。
首先,尽管各家都在极力宣传,但是正如我以前文章里分析的那样,即使Gemini这个1.3Q的月度使用量,环比增速也是明显下降了。另外,我一直引用的openrouter数据,尽管总量不大,但是它的用户有代表性。最新情况如下。很多迹象表明,token用量很可能增速已经明显放缓了。
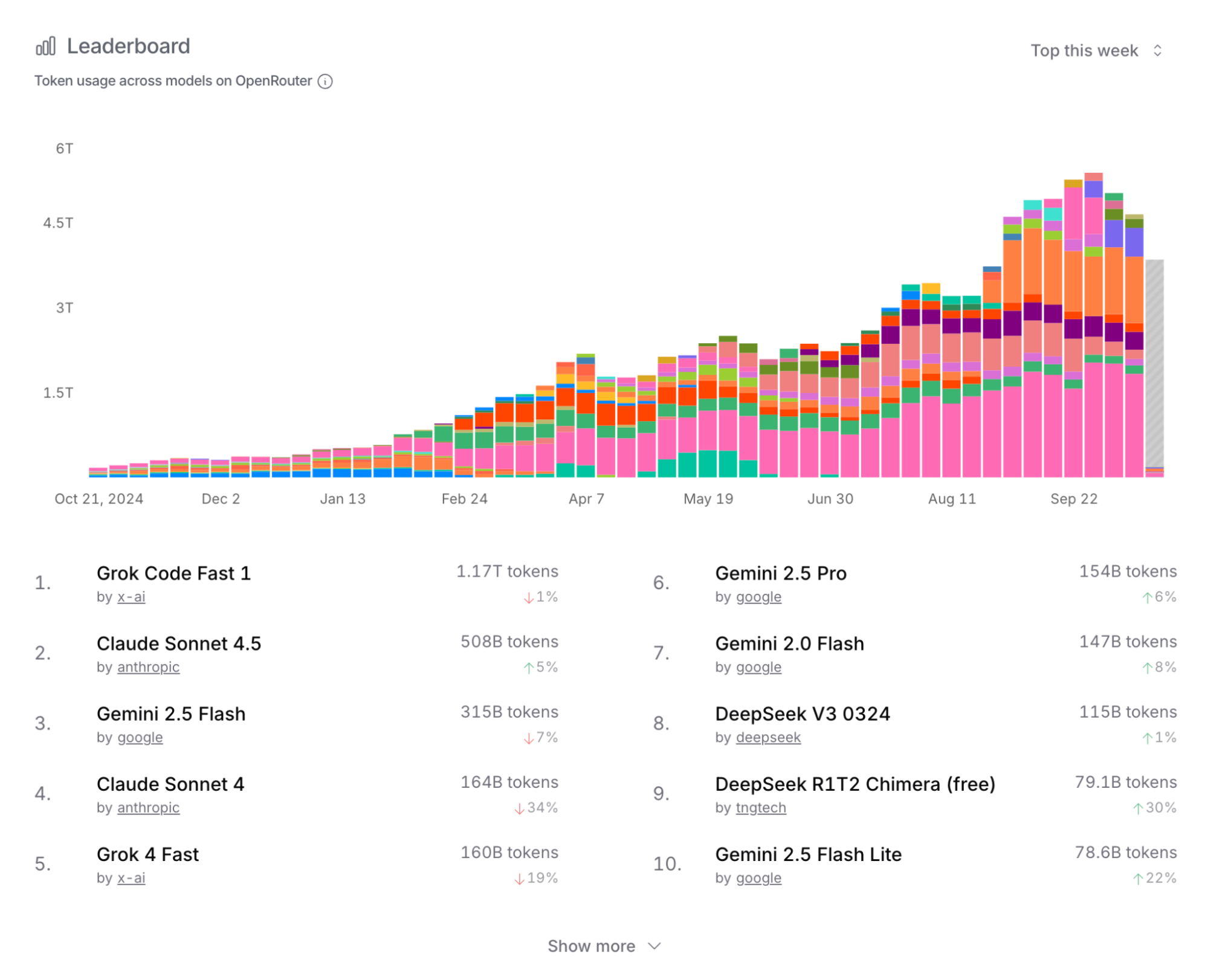
其次,会有人说本文开头提到过的Anthropic最新的ARR不断上调。这确实是一个很有利的AI Coding需求强劲的证据,一会儿讨论。
还有一些观点,包括我也会支持,GPT-5发布后,特别是codex更新后,效果很不错,token用量应该也是大幅提升的。
我想,从个人体验,社区交流,AI能力边界来讨论,基本上是一些客观上的更多主观结论,所以完全可以质疑,但我也找不到更多更有说服力的数据了。
前面说过的天花板的前提条件,压缩率,依然是我认为非常重要的约束。虽然在AI Coding里,压缩率极高,但是,各种原因下,至少我和为数不少的最近交流多的朋友,都会有一个非常切身的体会:个人的token用量基本不增加了。原因是两点,第一,目前AI能力下,人还是需要时刻关注AI工作的进展,随时打断,调整,甚至随着越多的开始进行生产落地的项目,这种人的参与比例就越高;第二,人的生理心理极限,长时间的人机协作,会让人感觉更疲惫,思想枯竭,反应迟钝。以上两点,没有因为模型能力的所谓提升(比如Claude3.7到4到4.5)而有改变,反而更严重;
既然是写代码,那么怎么能够在可控的成本下,获得更好的效果就是首先考虑的问题。这一点逐渐变成了用户与厂商之间的“博弈”。能用好模型的用户恰好都是可以最大化使用量的一批,更是希望“薅尽厂商羊毛”的一批。所以我们看到当厂商受不了高昂的推理成本而纷纷推出限流措施时,用户明显的流失了,最早是cursor,我大概三个月前停掉了订阅,转而完全使用Claude Code,如今大家都明显看到了cursor用户数据的快速下滑。最新的情况是,即使Claude Code和Claude模型可能依旧是最好的coding模型,但我已经基本迁移到GPT-5驱动的codex了。所以,有没有可能,在没有一家能垄断模型的竞争格局下,这个市场就已经快速提前进入存量市场了?
接上面,从Claude Code转向Codex的绝对不是我一个人,而已经成为一个很有代表性的趋势,据此,我对Anthropic对于以后的收入预期持较高的怀疑态度,但这需要些时间体现出来。他们也出了应对,Claude-Haiku-4.5,可是我目前跟codex磨合的已经不错了,我也知道比haiku好的sonnet的能力,所以,我几乎没有尝试haiku的想法;
归根结底,用量的提升都需要模型能力来保障。但,我们还忽略了一个因素,回报率。是的,我确实看到了很多类似于我这样的“老人”要么回到“一线”,要么越来越多的参与“一线”工作,当然,在AI的加持下,也接触了很多团队的一致观点:需要的人少了,可以做的内容多了,更忙了,当然,其实业务收入就还是正常;
我本来想讨论AI能力边界在哪里的问题,但想想,何必去讨论这些呢。因为有一个更现实的约束放在这里:收入;
用量当然还可以快速增长,但是技术进步带来的成本下降也很快,我们需要比较的是用量上升的速度和成本下降的速度。我大概有把握,明年每token的生成成本下降三分之二。所以,我们大概需要一个用量增长三倍以上的最低预期;
我大概也有把握,依然不会有任何一家垄断模型,在竞争性的市场里,用户总是拥有更多的选择权;
最后,一如既往,我不会低估AI对我带来的巨大改变和对社会带来的潜在巨大改变。但我也知道这依然是一个关于人的约束,模型能力约束,成本收入约束的三角形,虽然不是不可能三角,却只能在相互拉扯里前进,而不是一蹴而就。