假期结束,将期间的消息和自己这段时间的尝试与思考简单汇报一下,当作假期作业。
一、模型发布节奏
Anthropic更新了Claude Sonnet-4.5,在代码能力方面比4.1是有较为明显的提升的,但是不太清楚是模型问题,还是应用开发的问题,包括我自己和几位朋友在内,都出现了Claude Code强退的情况,初步看起来可能是因为后台进程内存和CPU消耗过大的问题;
Gemini-3即将发布,客观而言,GPT-5整体最多跟Gemini-2.5和Claude-4持平,Claude还有更强的代码能力,Gemini则是完整的多模态能力,如今Gemini-3发布在即,OpenAI已经落后了。
这大概也是他们为什么这么着急的锁定“未来算力”:按他们的路线当然非常缺算力;急于把故事做很大,否则玩不下去;试图限制其它潜在竞争对手。
Grok-4也做了更新,定价还更便宜。目前,它开始进入我需要重点关注的列表内了,其实,GPT最大的潜在竞争对手可能就是Grok。
二、Sora-2与多模态
从视频能力而言,Sora-2至少没有明显优于Veo-3,音画同步,语音和嘴形匹配,物理真实性方面,Google的Veo-3都已经领先了几个月了。即使现在的Sora-2,如果我们把社交那部分抛开(很多都是单人或者双人的,场景都不复杂),在信息量上,Sora-2可能还不如Veo-3。
腾讯的混元3.0发布,文生图模型可以支持中文渲染了,整体效果确实不错,但是相比Google的nano-banana其实还是有很明显的差距的,就是在质感和信息量上。
能看出来Gemini系列模型在训练数据上的巨大优势。
(同样的复杂提示词下,与真实场景的契合度可以直接反映出训练数据量的)。


说回Sora-2,即使不谈版权争议,一群人鼓吹的“颠覆好莱坞”,“颠覆抖音”,未来不是不可能,至少还有很长路要走。
至于说这种多模态是不是会产生巨大的模型调用需求,产生巨大的收入,答案在每个人心中:现在的效果你愿不愿意付费。对我而言,包含在订阅包里,作为一种补充,很好,但是用量,根本不可能跟搜索和代码生成去比较。
我确实认为也反复说过,后面带来巨大用量的是多模态,但不是这种,而是基于Gemini的文字、代码(前端可视化)、图像、视频加语音甚至音乐融合在一起的多模态。比如我现在每个交易日会发的视频:因为它改变了日常的工作流程,而且因为多模态的引入,提升或者至少是丰富了产品形态,同时,到受众那里是有巨大的信息压缩率(全网搜索的信息最后汇聚成一张图,一段语音,一段视频)的,背后是有非常强的scale up和标准化大量产出的逻辑的。
视频生成模型,离这个还有距离,可以提供素材,但还不能离开人独立成为产品。
三、OpenAI和算力投资
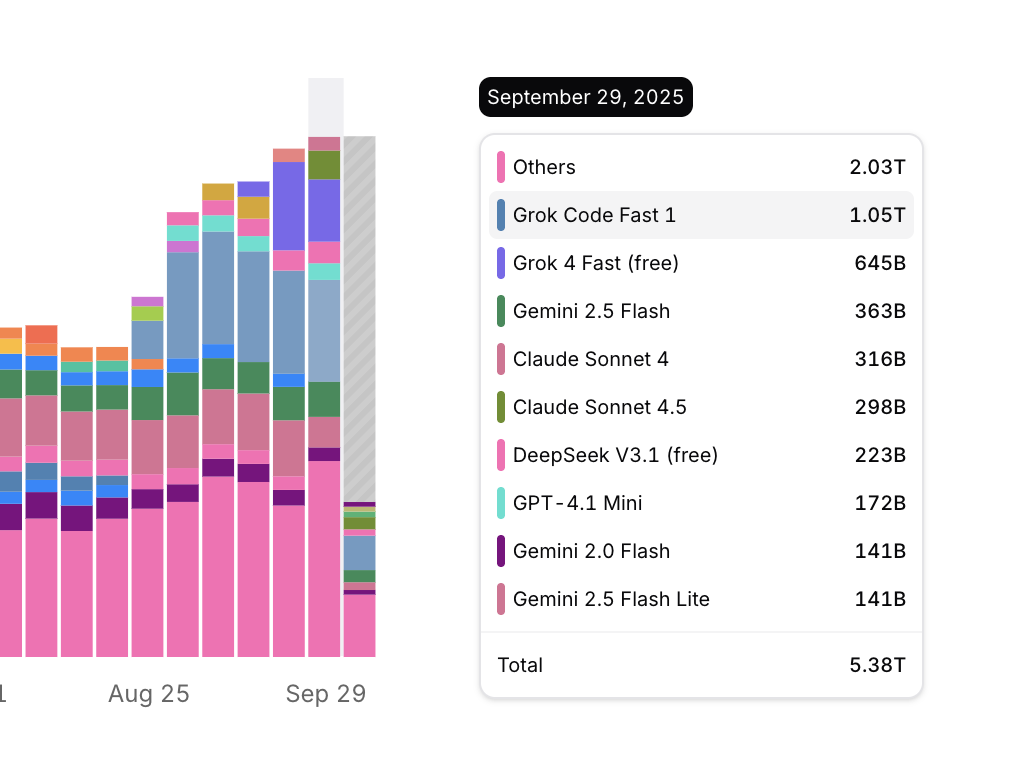
我在考虑OpenAI到处合作,给出巨量“未来投资额”的问题的时候,其实最终就是两个数字,一是Google自己论文里写的平均一次Gemini的请求,能源消耗是0.24Wh(https://cloud.google.com/blog/products/infrastructure/measuring-the-environmental-impact-of-ai-inference);另一个数字是如果今年英伟达生产的高端芯片在明年全部上架投入使用,需要超过10GW的电力,假设依然有一半用来“逐梦AGI”,剩下一半用来做模型推理,利用率80%,也就是4GW,全天就是96GWh,除以0.24Wh,400B(4000亿)次Gemini请求。我们可以假设未来的模型请求越来越复杂,单次能耗不止0.24Wh(虽然,这个假设根本不符合科技进步的规律),也可以假设用量非常大幅的提升。但是,参照我刚从SimilarWeb上的截图。前二十大八月份的访问次数总和看起来都不超过200B,平均每天7B。(https://www.similarweb.com/blog/research/market-research/most-visited-websites/)
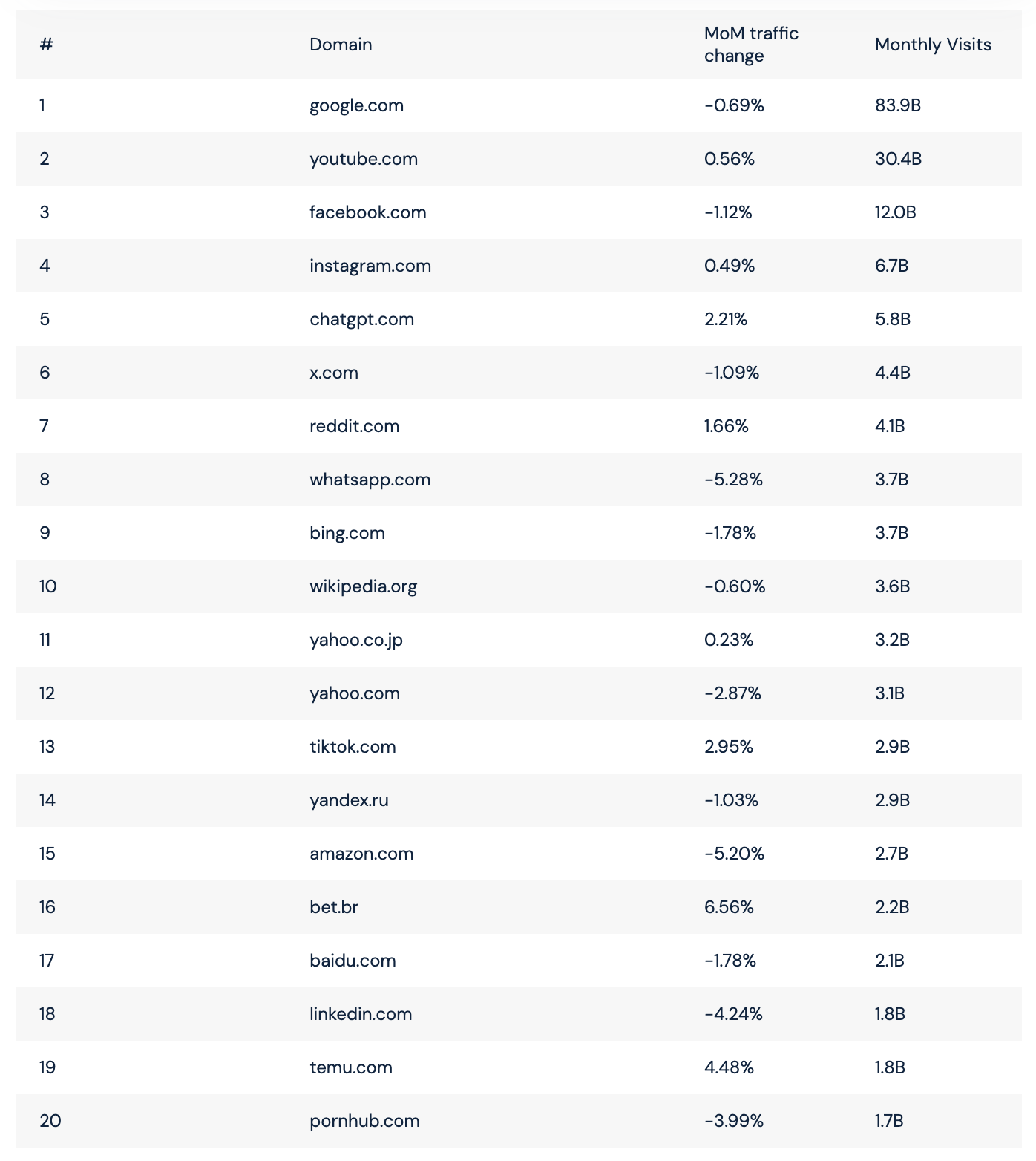
如果再考虑模型厂商一直在“鼓吹”的单次推理耗能会越来越低。以上这些,还可以得到“算力紧缺”的结论吗?
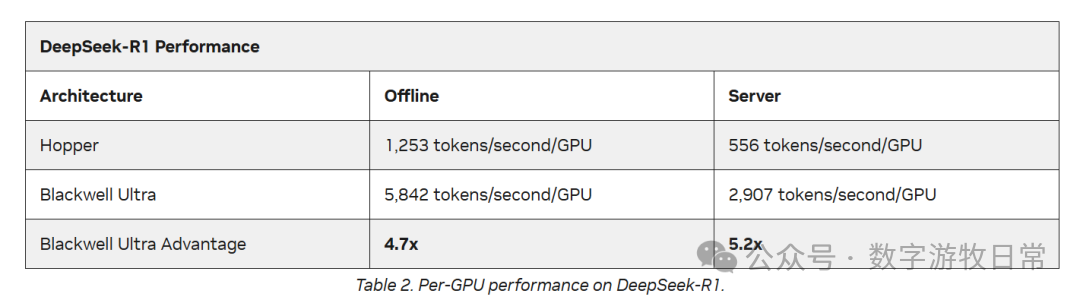
终于有公开研究开始讨论Oracle云OCI的毛利下降问题了,其实几个月前,市场几乎就是这样一致认为的。当然,对于BlackWell是否导致更低的毛利,我没有明确的结论,但是我很担心一件事情,在之前的文章里也说过:英伟达发布NVL-72时号称推理性能相比Hopper提升20倍以上,但是最新的MLPerf测试表明提升不到10倍,我在以前文章里也贴过。如果这是真实结果的话, 我担心的是大集群优势快速被“摩尔定律”的引力消耗掉。
四、国产模型
假期期间,我试了很多国产模型和Agent,也写了一系列文章。必须承认,模型是有差距的,但是在Agent加持下,能够应付很多场景了(很多场景的要求也没那么高)。有一个事情很有意思,国产模型总是落后于海外模型半年左右推出差不多同一代的产品,实现类似方向的能力增强,比如思考,比如代码生成,比如Agentic。这背后当然有相对确定的原因,不过就点到为止了。
但是,MiniMax,Kimi总体还是比我预期的要好的。一键生成一些内容网站还是可以的,虽然几乎无法扩展。比如:

https://heuhrk3m7qjs2.ok.kimi.link

https://emcqvix47v7b4.ok.kimi.link
https://vxfismw2bmmss.ok.kimi.link
假期里有点惊喜的是混元系列,虽然前面说了生图模型还是不如nano banana,但是混元系列的多模态布局战略意图是很明确,很清晰的。至少从现在开始,市场逐渐就会要求模型公司跟Google一样,在各个模态上都有不错的储备,然后可以依托生态融合,不断产出全新的产品形态。
当然,关于生态,老有一些自媒体在说ChatGPT有生态,我觉得这个说法太过小看“生态”这个词了,微软有生态,苹果有生态,Google有生态,Meta有,抖音有,腾讯有,但ChatGPT就是个有先发优势的应用而已,要不试试一年不更新模型而竞争对手更新两代?
所以,在我看来,纯模型公司没有一家有资格谈生态。
五、最后一个问题,如果AI模型就是一个软件?
无论“吹鼓手”说的如何天花乱坠,文本模型也好,图像视频模型也罢,它们没有任何我们人类认为的“智能”,现在的模型还只是个对于确定目标实现经常会出点小状况的“优化函数”而已,在我看来,它更像是一个高度自动化的软件,而不具备“智商”,更别说什么博士生智慧了。
也许以后有,但是不是可见的这几年。
那么,如果在那个有“智商”的AGI出来之前(如果可以出来,我们也不需要讨论什么了),这个可以自己生产软件的高级软件,就还是个软件。
对了,是一个一旦不领先,就几乎会快速失去市场的软件,它还有如下特点:1.必须靠不断更新来保持领先;2.每次更新都代价不菲;3.看起来,也没有一家可以完全垄断,意味着毛利率提升的空间很小。
三十多年前,当我还是个小孩子的时候,程序语言让我觉得是无所不能的,如今,我依然觉得模型是无所不能的,但我更相信所有的变化都只是在以较快的速度渐进的发生。
我只是,不太相信,“鬼故事”。