
我依然是那个当DeepSeek R1发布,市场一片“算力不重要”的声音时,坚持认为“算力需求无上限”,“NV在100-110就是很便宜”的我,也还是这个要“算数”,考虑“物理”的我。
今年一月份,当孙正义,埃利森,奥尔特曼在白宫站在总统旁边宣布“星际之门”计划时,投资的数字就是5000亿美金。
但很可惜,DeepSeek R1的发布和紧接着四月二号的“关税冲击”,把“算力”从高峰打落到低谷。
八个月后的当下,数字差不多还是当初那个数字,情绪却早已不是当初的情绪。
正如我过去很长一段时间里一直说的:缺算力会是一直持续的话题。
然而,我脑中依然会不断闪现Physics,这句话写在了英伟达在ChatGPT问世前介绍CUDA的PPT中,也是这几年里,对我影响最大的一段话。
Nvidia GTC 2022:How CUDA Programming Works.
所以,这一篇,无关“泡沫”的情绪,无关投资,只与一些物理有关,更与今年以来的一系列观点有关,感谢不断写文章的自己,阅读量高低虽然是一个挺重要的指标,但是能够不断整理思路,能够不断留痕回顾,要比阅读量重要的多。
我喜欢没有暴涨之前的英伟达,因为你真的可以从他们的各种材料里找到足够多的技术细节,你真的可以感受到那种脚踏实地“解决问题”的状态;
我也喜欢ChatGPT发布之前的OpenAI,同样,他们就是在解决一个个问题:当你利用他们的开源代码复现一个数字世界里的“人偶”从学会站立,到行走,到奔跑时,当你真的可以训练出一个规模很小的GPT模型时,你真的依然可以与那种“纯粹”完完全全的连接,并从中获得力量;
当然,我有多不喜欢如今的英伟达和OpenAI,我就有多喜欢Google,我有多不喜欢现在的老黄和Sam Altman,我就有多喜欢Demis(也许仅仅因为他就希望AI可以帮他做出Open World的游戏,仅仅因为他现在就想可以有更多的时间去玩《文明》)。
当人脱离“物理”时,就会有很多奇奇怪怪的表现,我的一位前同事把这个叫做“这个世界是属于偏执狂、疯子和神经病的”,我对这个结论百分百同意,但我对这个结论后的推论百分百不同意:那些偏执狂、疯子和神经病“改变”了世界,不代表只要是“偏执狂、疯子和神经病”就可以了;同时,那些依靠疯狂获得“成功”的人,是不是能够继续获得成功,这个问题的答案也显而易见。
我体会过“失重”的幻觉,我也见到过太多“因为我过去正确,所以将继续正确下去”的“登楼塌楼”……
所以,回到“物理”,对吗?
“物理”有两面,在未来的时间里,我仍将花费更多的时间去补充更多的细节,今天,精炼到一些数字,一些结论。
“物理”的第一面是供给:
如果按照市场一致预期的今年和明年算力芯片(不考虑国产芯片和销售到国内的芯片)的产量,算上服务器,交换机,网络,制冷等等一系列额外设备功耗,总的功耗需求量大约是两年25-30GW的水平。全球除去中国以外在今年和明年可以新增的数据中心容量大概是20GW的水平,要知道,支持AI的超大算力数据中心还只是其中的一部分,虽然这个占比很高;
很多人都已经知道了这样的现实:因为建筑结构、电力、水力供应和散热等问题,大部分的先进算力都需要装到新的超大数据中心里。所以我们几乎不用去讨论能不能利用现有数据中心,淘汰落后算力,装入先进算力这个可能性了,这种情况当然存在,但是占比很小,相对于缺口而言;
所以,我们可以看到越来越多“幽灵算力”:它们被计入到了某些公司的收入中,却没有被装到数据中心的机架上提供真正的算力输出;
我们大概找不到足够准确的方法和足够一手的合规信息来计算“幽灵算力”的量,但是在最短一年半到两年就会更新一代产品的时代里,留给它不断增加的buffer并不大;
关于供给,我们依然可以算很多东西:电厂、光线、铜缆、电力设备、PCB,HBM内存,NAND存储,甚至机械硬盘,等等等等,这些细节跟“投资机会”可能密切相关,但“叙事”都只能在数据中心这本“大账”里;
“物理”的另一面是收入:
理论上,一张供需平衡表在供给的对立面应该是需求,但是AI不太一样,在很长一段时间里,可能都无法做到“羊毛出在猪身上”,那我们只能把需求更聚焦化:收入;
与互联网的流量时代不同,在一个“万物皆计算”的数字世界里,每一个token都需要对应着成本和收入,我们会说“杰文斯悖论”,虽然价格在快速下跌,但是只要用量上升的足够快,总收入还是增长的;
2025年至今,我们看到了这个趋势:token价格下到了2美金及更低的水平,相比去年至少是百分之六七十的跌幅,但是token使用量是按照每两个月到三个月翻翻的速度上涨的,模型公司Anthropic的ARR快速增长,OpenAI虽然没有确定的公开披露,但是ARR增速一定也是很高的,其他一些应用公司,比如Cursor,也有很夸张的ARR增长斜率;
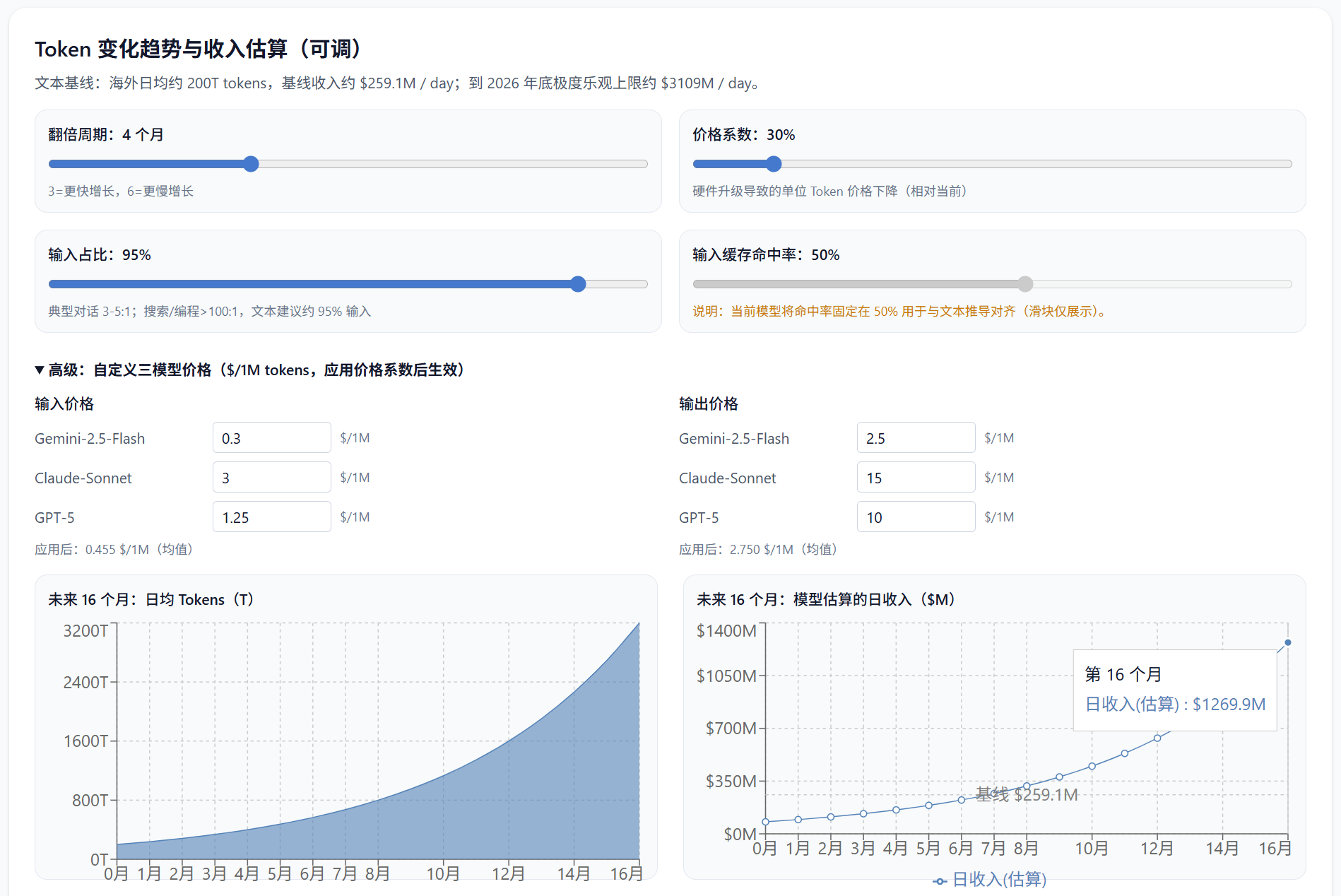
前几周,我做过一个弹性测算:以基于六月底公开数据及合理推测得到的八月底的数字(日均200T token)作为基线:如果未来token用量平均每四个月翻翻,到2026年底,token成本下降70%,那么2026年底,中国以外市场日均token收入大约为12.7亿美金,年化超过4600亿美金。但是这个数字会严重高估,原因是目前token用量里,可能有很大一部分是来自模型公司内部,还有不小的一部分虽然来自于用户,但却是免费的(比如Gemini每天都有很“慷慨”的免费用量,我几乎会用满,差不多可有达到1亿token,即100M的量,我相信全球我这样的人会有百万,那就是100T,很夸张,好吧,十万人?10T,这个数字是不是很随意?真实的除了几家模型公司,其实谁都不知道。)
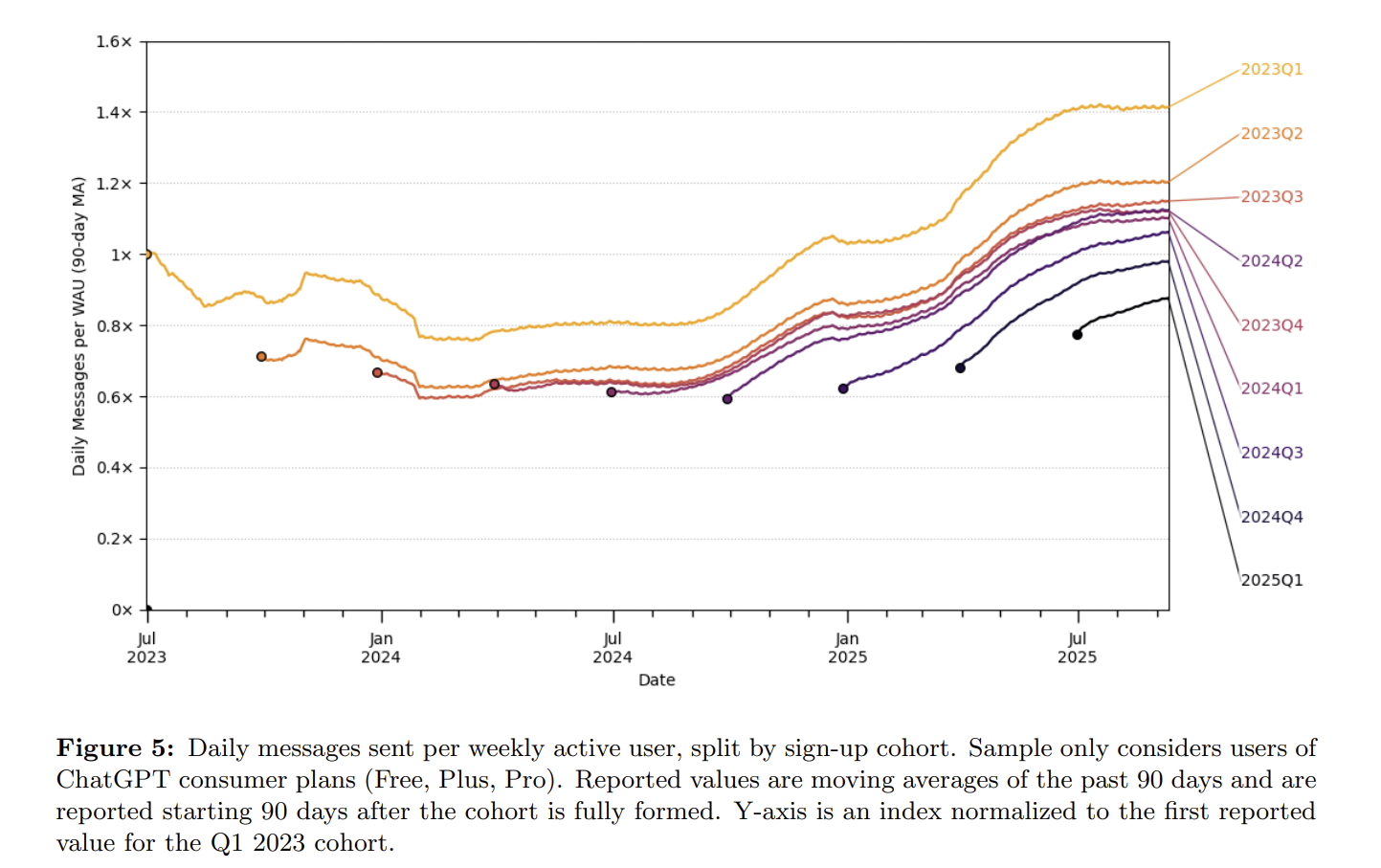
其实,我可能还是高估了这个增速和收入趋势。我用三张图说明,第一张来自于OpenRouter的模型调用排名数据,虽然每周5T不到的调用量占比很小,但是它的用户群却具备一定的代表性。我们看到如果没有价格更低或者免费的Grok模型的加入,token环比增速已经基本持平了。公认代码能力更强的Claude调用量已经稳定了很长一段时间。我没有进一步仔细计算,但是考虑到Grok更低的价格,从收入角度看,大概我们可以看到的趋势就是flat:因为搜索和代码生成带来的token高增速可能已经进入瓶颈期,用户对token价格依然极度敏感,在模型之间没有特别显著差别的背景下,低价模型的替代效应很明显。
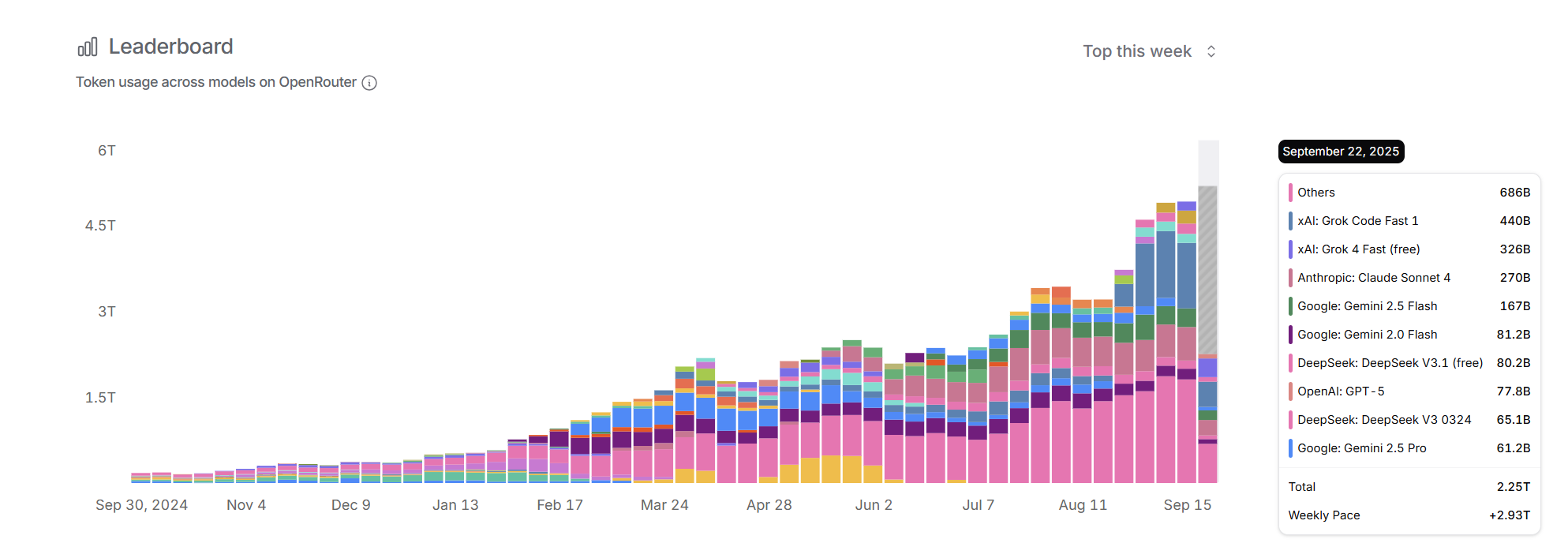
OpenRouter Rankings
OpenAI发布的GPT用户画像数据则讲述了另一个故事:一个完全在ChatGPT应用中的画像:用量提升主要靠增量用户,在应用的环境下,存量用户的日均使用次数增长是很缓慢的,完全达不到几个月翻翻的状态。有人会说,思考模型出来后,模型思考更长,回答的内容也更长,token量会增长更多,这个当然。但是,如果你是用户,你会为愿意为一个日均使用次数一年里增长了大约百分之五十的应用多付百分之五十的费用吗?有人会,但绝大多数人不会。
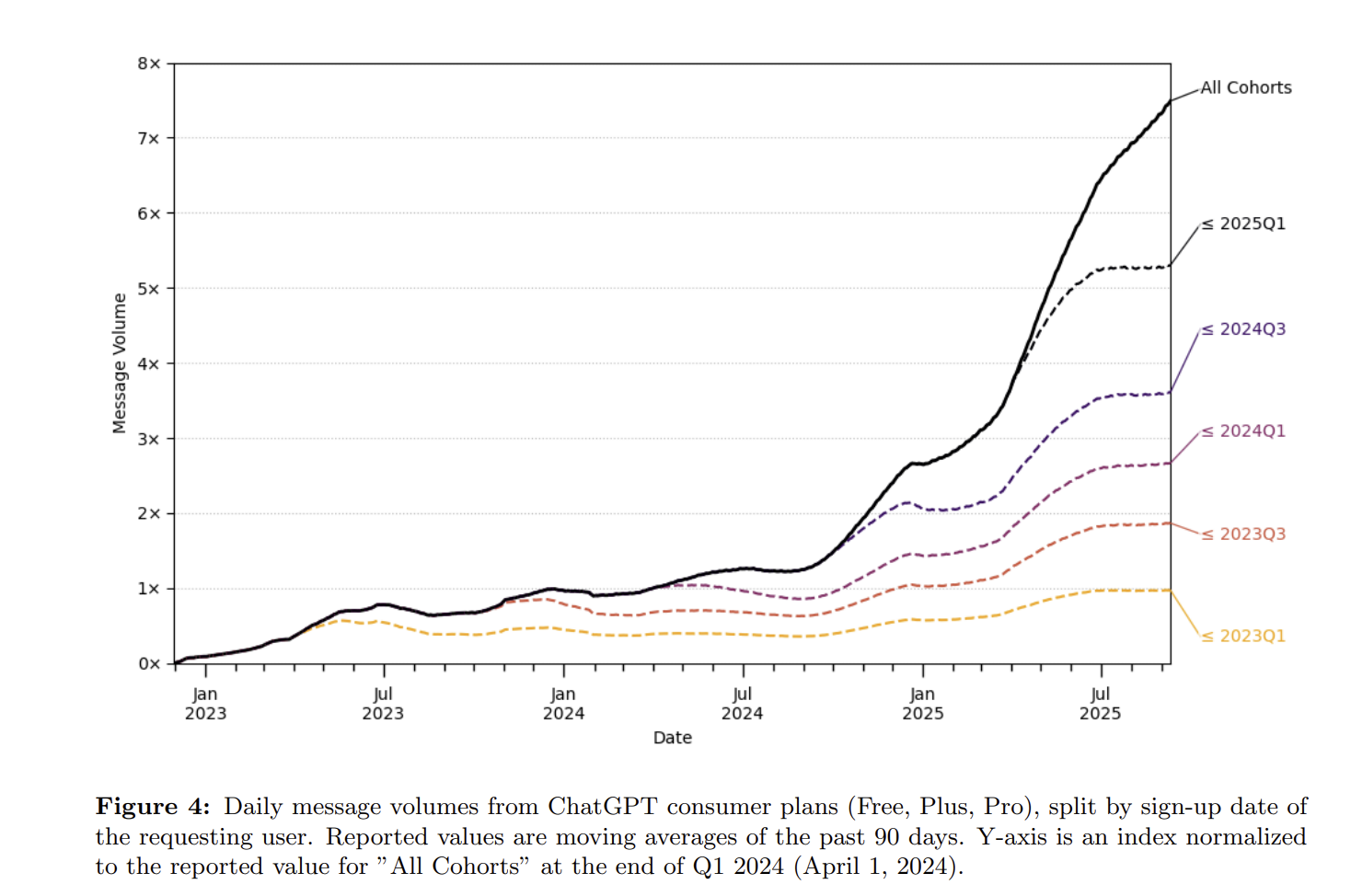
OpenAI: How people are using ChatGPT
我们几乎可以得到这样的结论:真正带来token用量大幅增长的是AI搜索和AI代码生成,今年以来,这两项拉动的增速远超过市场之前的预期,但是渗透率存在天花板(Anthropic最近报告里的调查局数据)和低成本模型替代效应的双重作用下,增速衰减又可能比预期的更快;
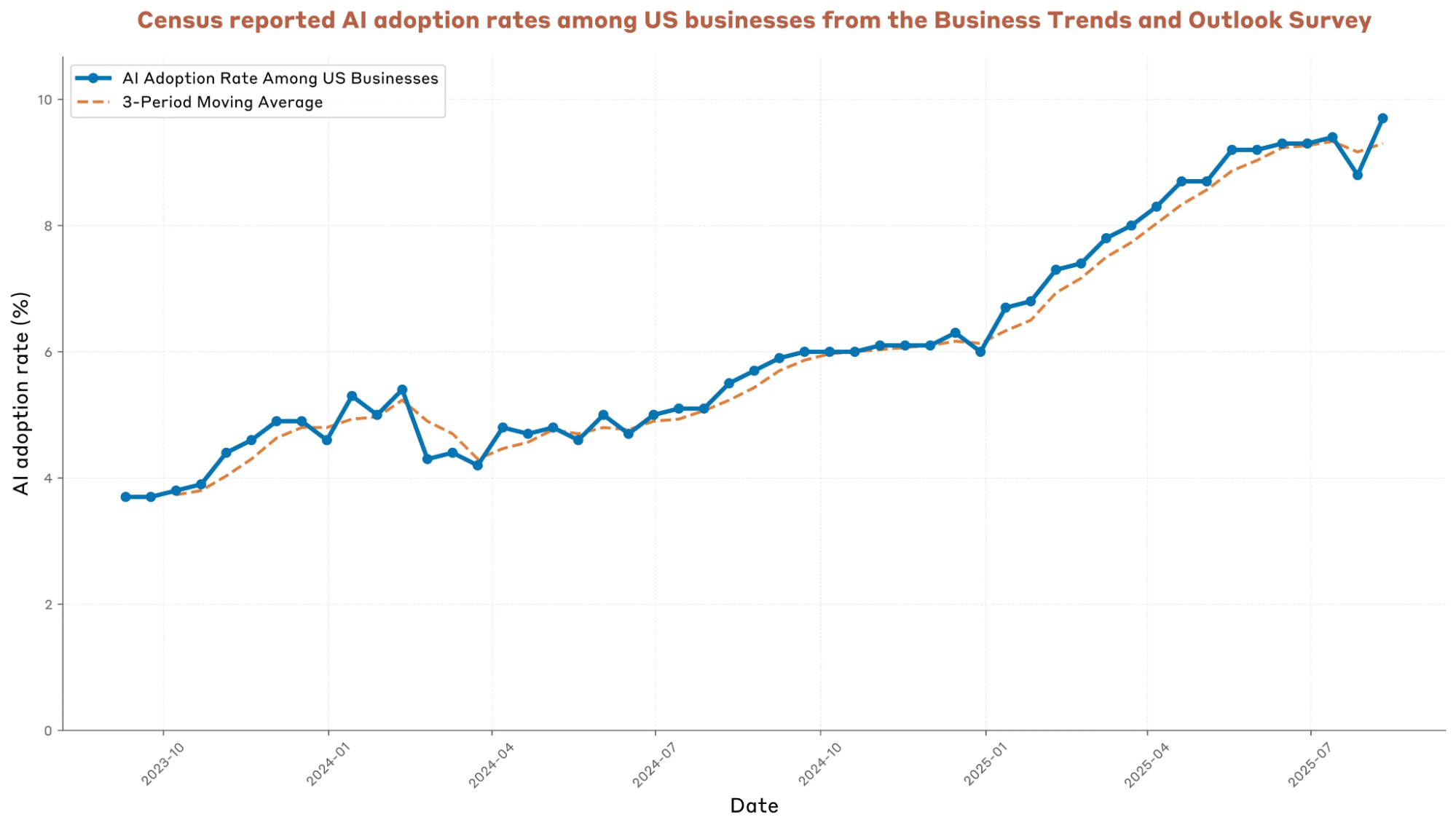
anthropic-economic-index-september-2025-report
到这里,我们还有一个问题没解决:模型还会进步啊,还有AGI或者ASI,那时候用量肯定会再次大幅提升的。
是的,或许都不用到那时候,多模态就可以带来用量的提升了,看看Gemini-2.5-Flash-Image(nano banana)模型发布后有多火,Gemini应用的日活数增长有多夸张就知道了。
但是,仅图片带来的token用量的量级,跟搜索和代码开发在量级上是完全不能比较的。一张图片就是几百个token,生成图片所需要的算力其实也比想象的小,看Google对模型的收费标准就知道了,百万文字token的输出对应大约70张图片,这很夸张了。有人问,那图片输入为什么要0.3美金,想一下一张图片动辄几M,虽然在transformer里也就对应到几百个token,但是传输,存储,tokenize都需要成本。只不过,传输和存储不需要用到算力而已。
好,再往前看到AGI或者ASI,我们的假设是用户一定会愿意付出夸张的价格。我同意,如果真出来的话。
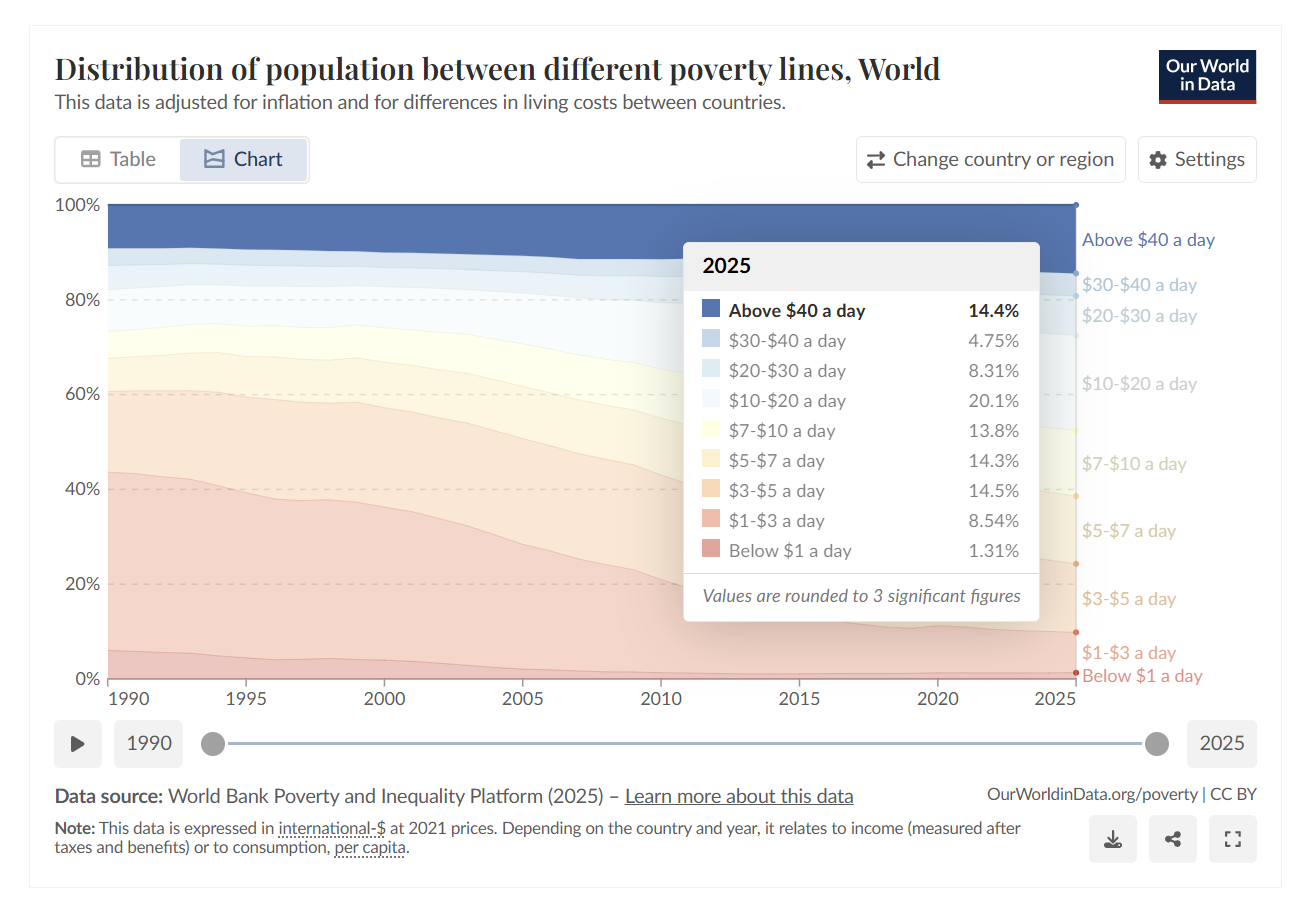
但是,又一个隐含的“物理”出现了:AI存在于数字世界之中,但承载它的一切存在于物理世界中。我们假设老黄和奥尔特曼不是在吹牛,我们假设五年以后,计算带来的市场就是三四万亿美金。但是如果我们不相信这会带来全球GDP每年20%的增长,我们还是愿意相信世界经济增速可能就是在一个相对正常的增速下:三四万亿美金的市场一定对应着至少等量劳动力的重新分配。
如果,我们再看到“计算”提高的效率部分正是现在渗透率最高的那些领域的话,物理又出现了,按照世界银行的收入分布统计数据,我们很容易做一些数学的。
写到最后,我知道上面的讨论,其实改变不了任何人的观点。但我不是一个观点极端的人:我相信“计算”的威力,我每天最多的时间都在跟模型打交道,哪怕是一些细微变化,我都能感觉到,我相信“光”的未来。
我只是,更愿意相信“万有引力”下一个合理的计算。
我知道,自己在很多人眼里已经很偏执,很疯狂了,但我知道自己不是偏执狂,疯子和神经病,我曾经努力过,但失败了。
我依然相信,在2028-2030年里的某个时间,在极度乐观的场景下(也许全球GDP真的可以有两位数的增长,也许癌症真的被攻克了,也许可控核聚变就可以让能源变的很便宜,也许全民“富裕”的时代很快就会到来),真的会有某家或者某几家模型公司的年化收入达到2000亿美金以上,让5000亿美金的资本开支看起来一点都不贵,即使考虑高额折旧的情况下。
但是,我更愿意相信“物理”,也更愿意相信自己二十年来接受的经济学常识训练。
最后一句话,一方面看,“泡沫”是显然存在的,但另一方面看,真实的基础又是坚固的,只是时间和程度的问题。但是,我不喜欢为了卖东西而不断放卫星的行为,因为这个赌注不是一两家公司,而是我们人类自己。