在一个Deep Research的任务中,模型搜索并引用到了来自Stack Overflow的调查,是的,前不久刚看到关于Stack Overflow基本“死了”的分析,它做的关于AI的调查还可信吗?
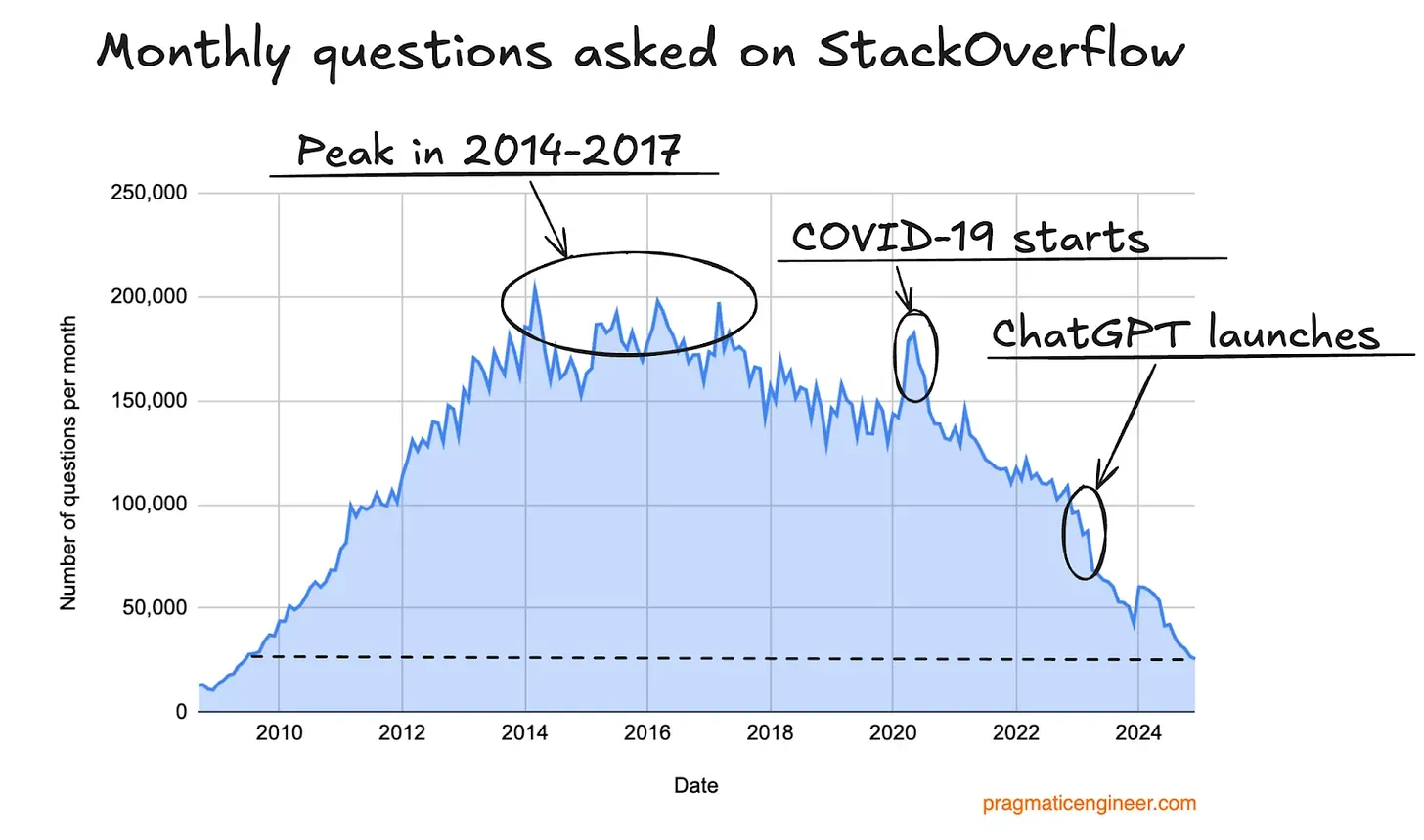
这不会是一个怀念什么问题都能在Stack Overflow上找到解决方案的时代的文章,所以关于它的前世今生,一笔带过,只贴一张那篇“Stack Overflow死了”的帖子里的一张截图:提问数的。
贴这张图,其实也可以去给出一个假设,后面关于调查问卷的统计数据,可能样本里的“程序员”,都经验丰富,甚至偏老了,处于微笑曲线的右半边,所以代表性的部分,需要从右半边来考虑。
首先,这是Stack Overflow 2025年度调查(https://survey.stackoverflow.co/2025),每年会做一次,所以所以要说代表性,随着时间推移,显然是在下降的,但是代表性也一定是不错的:调查统计来自177个国家和地区的超过49,000名程序员回答的问卷。
里面涉及到了很多方面的问题,我主要挑关于AI使用方面的,先出总体结论。

很显然,这样的结论体现了上面所讨论的用户“向右偏”(样本基本都是程序员,且时间偏长),Stack Overflow官网的画像数据也很清晰的显示出了这点。

为什么要强调这一点?我们可以很明显看到在AI Coding如火如荼的今年,尽管采用率上升了,但是信任度下降了,不信任度却明显上升了。

只能说明,相对资深的程序员早在去年开始就开始较大规模使用AI Coding(去年六月份Claude 3.5发布为“拐点”)了,而且是蜜月期。今年使用率上升,信任度下降,不是说模型变差了,而恰恰是证明了这批用户开始将模型用于广泛的多且复杂的多的实际任务中了。
他们对模型最大的挫败感来自于:看起来正确,但是有很多小问题,调试需要花费更多的时间(前一个问题我一直在说,后一个问题我承认,但是最近我逐渐知道这是没有用对方法,后面的篇幅重点讨论)。

另一个说明的问题是:参照下面的2024年的用户经验分布,虽然时间划分有了区别,但是很明显,2025年的用户比2024年确实又“老”了。于是,一个对于今年AI Coding火热的大胆猜测是,今年用户渗透主要是“年轻”程序员和非程序员。

另一个跟我们的“体感”不符的是IDE环境的使用:Cursor的采用率比我预想的显著低,应该也低于目前更大样本用户的实际情况。但是,这给了我另外一个问题的验证:经验更丰富的程序员是不是会更“顽固”?

这个调查里还有很多很有意思的细节,我不一一列出来了,希望感兴趣的人移步 https://survey.stackoverflow.co/2025/ 。在我开始写代码的时候,最好的参考资料只有桌上一本本大部头的《Language Reference》。而后来到了大量使用Python的那段时间里,是Stack Overflow帮我解决了很多问题,虽然时代趋势无法逆转,但是如果可以让更多人了解到,去看一下,甚至翻一下以前每年的数据,可能也会挺有意思和收获的吧。
回到开头,如果不是Deep Research帮我找到了这个素材,我几乎忘记了它年度调查的存在。其实,我以前也从不关心(不是为了写文章,谁关心别人在干嘛呀)。甚至写这篇的目的也不是因为要说调查结论,只是恰好跟我脑子里存在了一段时间的问题有了碰撞。
问题是:如果我们开始认为目前的AI是toP(to Professionals,专业人士)的,那问题在哪里?
我的周围到处是两种专业人士:分析师和程序员。我也知道很多人跟我一样,大量的开始在日常的“工作”中使用AI。
但是,当我有意识的去搜集他们的反馈时,我得到了很多类似于上面统计数据呈现出的结论:用的越来越多,但是也越来越觉得“AI无用”,甚至浪费时间,那种“看起来很对,却bug很多”的挫败感。
我理解他们在说什么,程序员总是认为AI代码没自己写的好,还浪费自己调试时间,分析师认为AI给的结论根本没用,看起来很完整很专业,但是专业人士哪会只看这个啊?
也许,“保守”永远正确,可是更多时候,就如Stack Overflow一样,你还在认认真真按部就班的做着跟以前一样的事情,看不起任何“年轻人”,时代却早已把你包在一个“茧房”里,任由你自己枯萎。
在我和我所处的群体组成的这个被包围的“茧房”里,我有信心自己是最“叛逆”的那批,更是AI使用量最大的那批,我承认它们所有的不足,但是我看到了它们无法想象的进步速度。我承认我的同事和伙伴们抱怨的每一个缺点,但我也知道,更多的可能是我们用错了方法。
我们总拿AI出的报告的结论和判断来跟自己的经验做比较,但是我们的经验来自于哪里?与其说是时间的积累,不如说是数据的沉淀,可是数据分明就是AI最大的优势啊!我们依然可以说,有很多“私域”数据AI获取不了,连阿拉斯加峰会里的一些核心内容都会被泄露,还有多少“私域”数据是真正“私域”的?越来越小的“茧房”数据吧!
我们总说AI的代码bug很多,安全性有问题,执行环节有很多逻辑错误,效率也不高。但是想想一年多前,我们对于它可以生成些交互式网页都觉得很兴奋,再早之前我们对它可以写一个函数都觉得“不可思议”,如今的Claude是真的在“接管”我们的项目啊!
如果一个模型可以在半小时里把前一夜的市场信息全部整理并分析一遍,那我们该考虑的是如何让它生成更符合我们每个人自己习惯的样子,而不是说,这有什么用?
如果一个模型可以在一两天里面完成一个功能基本正确的软件系统,那我们首先该考虑的永远是“需求是否正确”,而不是它够不够健壮,执行效率高不高(如果没有过配置下面文件经历的,没有过优化系统核心640K内存经验的,说执行效率,有点“呵呵”了)。

如果一个系统就是一两天由AI构建完成的,如果可见的这个时间会在明年变成半天或者一小时,被“软件工程”和《人月神话》长期“洗脑”的那些想法就该统统抛弃掉。
只有目标,没有软件,再说一遍,只有目标,没有软件。
虽然,上面这句话,也许在这个时间点看起来,依然天方夜谭,但我确实一直有点“叛逆”。
我很幸运,自己是程序员,是分析师;我也很庆幸,自己不是程序员,也不是分析师。
我们面对的AI,是我们无法理解,却是可以一路携手前行的伙伴,它的进化方向越来越不会是我们想要的,要改变的是我们,那些被规训了的“陋习”。