这不会是一篇详细的评测,只是这一段时间自己各种高难度“边界”尝试后,一个大体的主观评价,纯主观。可以分为几部分:
- GPT-5,Claude-4,Gemini-2.5,三个模型适用的场景;
- 三大模型网页版、手机APP与终端工具(Codex,Claude Code,Gemini Cli);
- 如果让我选择国产“平替”的话。
一、三大模型:GPT-5最全面,Claude-4最专最稳定,Gemini-2.5最深
距离GPT-5的发布已经一周,关于它们三者的感受与结论,其实与发布后那个周末的“第二感觉”变化不大。GPT-5的优势在于思考强度、Agent调用,以及舍得下“算力”。综合而言,是两点,模型层面是强化学习能力,使用层面是更“努力”。在绝大多数场景下,例如,问一些问题,做一些实时搜索,提供一些文档语料进行互动,产出一些结构化文档,GPT-5其实都能给出不错的答案。可以明显看到“思考”在其中发挥的巨大作用,如果开启“ChatGPT-Agent”模式,甚至很多时候还有一些惊喜。这背后更多是强化学习的功劳,无论是“思考”,还是Agent(其实就是工具)调用。
当然,这并非没有代价:思考与Agent调用的过程并非可控,大多数场景下,当用户要求GPT-5给出更大的“努力”,无论是调用级别更高的模型,还是提出长且具体的任务清单,这些都可以让GPT-5“消耗”更多的算力,然后得到更好的结果。我有一系列定时任务就是这么实现的。但是,但是,更多的思考和Agent努力,也往往意味着过程的失控。上面的截图显示出一个每日任务大概使用了22分钟,然而,这个数字每天的波动巨大,有不到二十分钟的,也有超过四十分钟的,甚至有过一次持续两小时(超时被服务端停止)。
这并非网络和系统响应速度造成的,看日志过程,就是会有大量的无效重复,或者错误的路径。虽然,目前看起来对结果的影响并不致命,一个持续的流程在最后往往有机会回到正轨,但是小瑕疵,任务遗漏,也是随时可见的。这也会有一个风险,GPT在历史上关于“降智”上的斑斑劣迹,模型总会在发布后经过一段时间的磨合与微调变得很好用,然后在大概三个月以后,开始变差,“降智”。如今看来,大概率就是“降算力”的原因。当然,目前,它可能还是最符合绝大多数用户绝大多数场景的。
Claude-4的优点和缺点都很突出。它毫无疑问依旧是“代码能力最突出”的,这点已经不需要再去描述了。但它确实也是目前三大模型里“幻觉”最严重的,这在大多数代码生成场景里不是个大问题,但是在日常使用中,就会成为一个问题。这个问题可以在下一部分再深入,涉及到一个对于Anthropic(Claude模型开发者)非常重要且致命的问题。
Gemini-2.5在Google生态里自然如鱼得水,是内核最稳定,同时也是延展性最强的模型。实际上,Gemini-2.5可能在每一项任务中都能在三大模型里排前二,在需要深度的任务里都可以稳稳的第一。但是,前提,就是“Google生态”。简单而言,就是会发现,同样一个搜索,可能在Gemini的APP里结果错误很常见,但是开启Deep Research后,事实性的结果又如此准确,在AI Studio中开启Grounding模式后,搜索结果也如此“精准”。
用久了,你也会发现,它会很聪明的偷懒,同样一个描述较为简单的程序任务下去,比如建一个关于某主题内容的网站,Gemini和Claude都可以完成,区别是,Claude可能加上了很多mock的内容,还会把页面调到它认为的“美观”。例如,一个C++学习网站。最近Tailwind的创始人出来澄清,我才可以证实那个一直存在的疑问:这种独特的“紫色品味”一定是学某种CSS风格“学废了”。
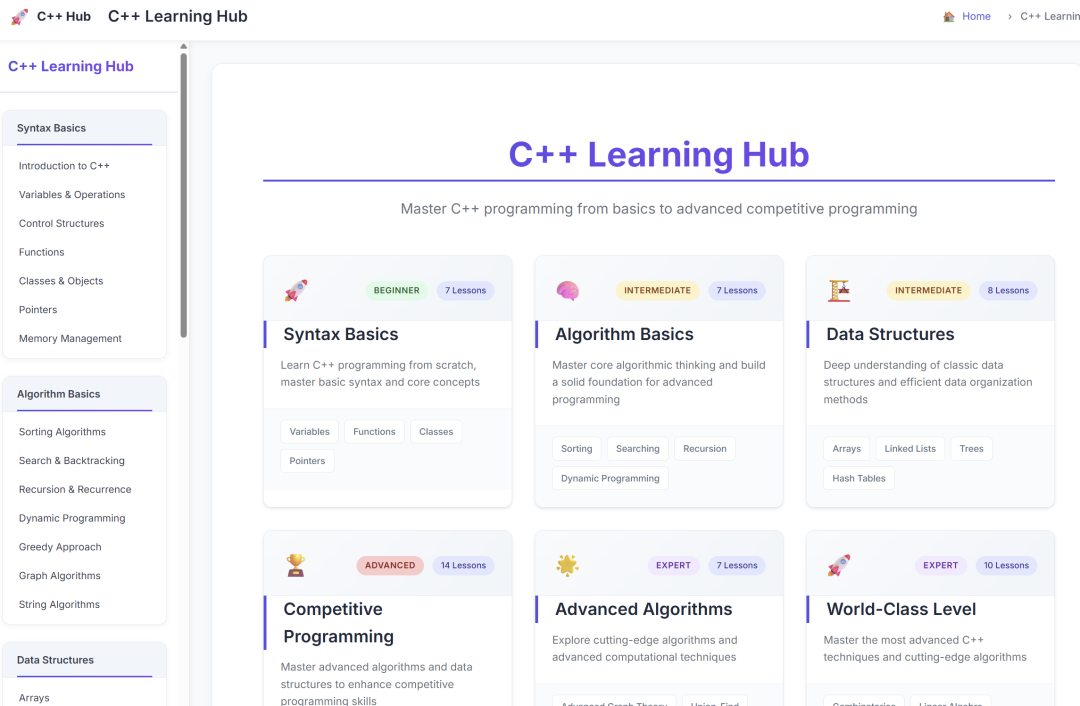
相反,Gemini-2.5从不这么干,除非用户给出很具体的要求,否则它都是完成基本任务,比如,上面的页面,目录是有的,卡片模式可能是有的,但是卡片可能是点不开的,因为没生成具体内容,CSS风格一定是因陋就简的,大概率就是最简单的黑白风格。Gemini-2.5能完成用户的任务,但是不会多给一些,你说它“能力不行”吧,同样一个网站,它的基础构架就是比Claude-4来的更合理,更简练,它生成的代码一次性通过的比例就是远远高于Claude-4。然后,当你把类似于上面的截图发给它,说“不能偷懒,要做到这个样子的”后,它又确实可以全部生成出来,甚至无论结构、内容,还是审美上,都要高一点点的样子。
很多时候,我都会有一种奇妙的既视感:面对Gemini-2.5,仿佛就是在面对Demis,一个天赋异禀,又无比狡黠的学霸。你需要跟他斗智斗勇,才可以获得更好的结果,当你认为这是自己“聪明”时,其实,它根本没在意过你。相比之下,GPT却活成了需要付出巨大的后天努力才可以成绩领先的样子,Claude更像是一个自以为聪明的投机分子。这才是我们绝大多数人真实的样子。
二、应用与终端工具
经历了一个周期后,三家都有网页版,APP,终端工具(GPT的Codex,Claude Code,Gemini Cli),还有一堆乱七八糟的其他工具(目前就属Google家最多,OpenAI也不少)。
前几天,我的帖子是,如果从“ChatGPT、Gemini、Claude、Perplexity”四个APP里删掉一个,会选哪一个,我的答案是Claude。如果,今天,换一个问题,只能留一个,我会留哪一个?答案是,ChatGPT。抛去Perplexity不说,在三家的APP应用里,如今的Claude是最没有场景的,因为写代码在手机上并不合适,需要桌面,需要ide环境,或者终端环境。Gemini因为上面提到的一些原因,很多时候,反而是在网页版和AI Studio里更好用。ChatGPT如今就代表了OpenAI几乎90%以上的努力和功能。
同时,我现在几乎不会在手机上用Claude的网页版(在电脑上偶尔会用,两三天打开一两次的频率),ChatGPT的网页版只在电脑上高频使用,但是我会在手机上非常高频的使用Gemini的网页版和AI Studio。虽然,我在不断增加自己“案头”的时间,但是在移动场景下:地铁,公交,外面跟人交流,我会通过手机访问网页版,讨论一些突发的灵感,或者安排一些离线任务。活跃用户数其实就说明了上面的情况,ChatGPT不仅基数大,日访问量还在快速增长,Gemini的日访问量在这个半年里也在快速增长以不断匹配Google的地位,Claude就乏善可陈了(Similarweb侦测的页面访问量包含手机端和网页端)。前两天,Similarweb在X上发了这个统计,可以说明很多问题。

但是,访问量区别的背后的原因也很复杂:比如ChatGPT不仅因为是最早占领用户心智的,也更因为它的免费使用量更慷慨,Claude对“免费用户”并不友好,等等。
三家的战场也在慢慢的扩大化和转移,现在一个完整可比的新战场就是终端工具,分别是Codex,Claude Code,Gemini Cli。就目前这种形态的工具而言,Claude Code发布最早,Codex Cli(OpenAI很早就发了codex,但是终端工具的形态,是今年四月份)和Gemini Cli跟上。在过去一段时间里,我对终端工具使用的时长快速增长,因为它不仅仅是个代码工具,更可以是一个全能的工作交互平台。我在上个月底开始的OpenResearch项目就是一个基于终端工具的使用场景,对我而言最大的变化是:大幅降低了很多自动化任务部署的复杂度,大幅提高了每日的产出。
在Cursor对用户越来越不友好(限制使用额度)的背景下,代码方面我已经基本转向了Claude Code。日常任务都在Gemini Cli或者自己写的一些其他基于Gemini的工具中。GPT-5发布后,我开始尝试Codex。Gemini Cli可能是最不可稀缺的工具,原因很简单,它有Google的Web Search工具加持,或者说,有整个Google的搜索引擎加持。而除了代码生成的工作外,其实最重要的两项工作就是,搜索,本地文件生成和管理。
我隐隐有一个判断,但还需要时间来证明,AI时代,Google的搜索引擎的价值不仅不会被削弱,甚至还可能得到更大的加强,这不仅仅是一个准确性的问题,还有一个Google长时间积累带来的“搜索成本足够低,搜索效率足够高”作为支撑。这方面,Claude Code虽然也可以发起搜索,但是准确性,就(其实Claude的幻觉本身就是相对高的,加上没有搜索的积累,结果就是错误百出)……
Codex在最近几天给我到惊喜,原因跟上面说的GPT-5有点类似。特别是我昨天给三个终端工具下了同样的命令,在一堆文章里,把所有的网页链接内容下载下来。Gemini Cli反复以各种花式理由“拒绝”我,在我“连哄带骗”下终于同意用web fetch来干活的时候,我停掉了会话,原因是这明显会快速消耗掉每日的请求次数额度。Claude Code基本没把任务搞明白。Codex很干脆,读了一遍所有文章,建立了一个下载列表,使用了curl和python代码两种方式去处理,还写了失败日志方便重新尝试,虽然干的很慢很辛苦,但是一个晚上后,我得到了很清晰的结果。Gemini-1.5之后我一直认为它是劳模,如今,劳模称号易主了。
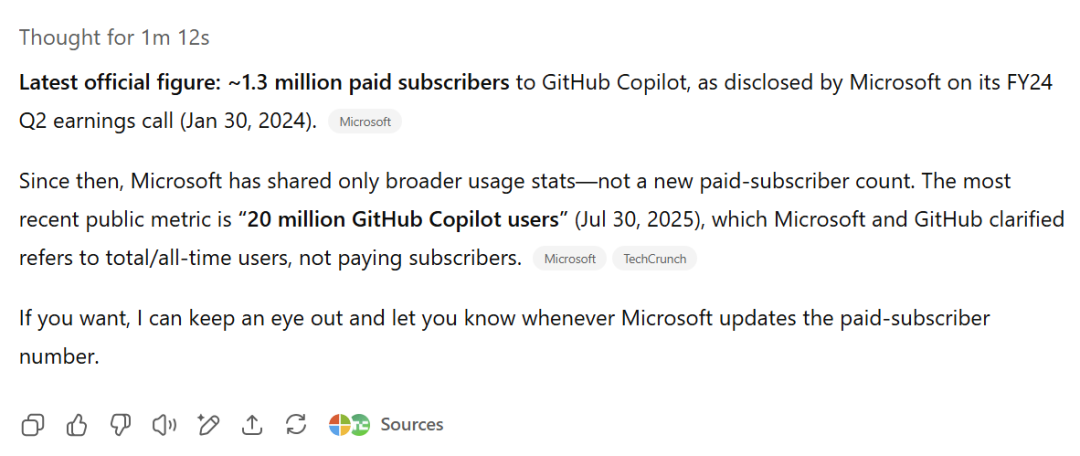
然而,终端工具虽然有可能带来更多的模型调用量,创造更多的收入(用户时长即收入),回到“终端”时代也确实让很多程序员着迷。但是在一个深度经历过Linux开发环境的人越来越少的时代,这样的用户很可能目前已经被挖掘完毕了。Github号称copilot用户在七月份达到两千万,从四月份到七月份增长了五百万,一个很合理的假设就是,因为AI Coding的渗透,大量其他领域的专业用户也变成了Vibe Coder。题外话,我在确认github copilot用户数的时候,问了一下Perplexity,两千万这个数字我是早就知道的,但是对于130万订阅客户这个数字我没有印象,因为我首先看到的是summary部分,所以在summary后的来源里没找到这个数字。然后我在给出的所有来源里看了一遍,终于找到了,24年一月份的信息。
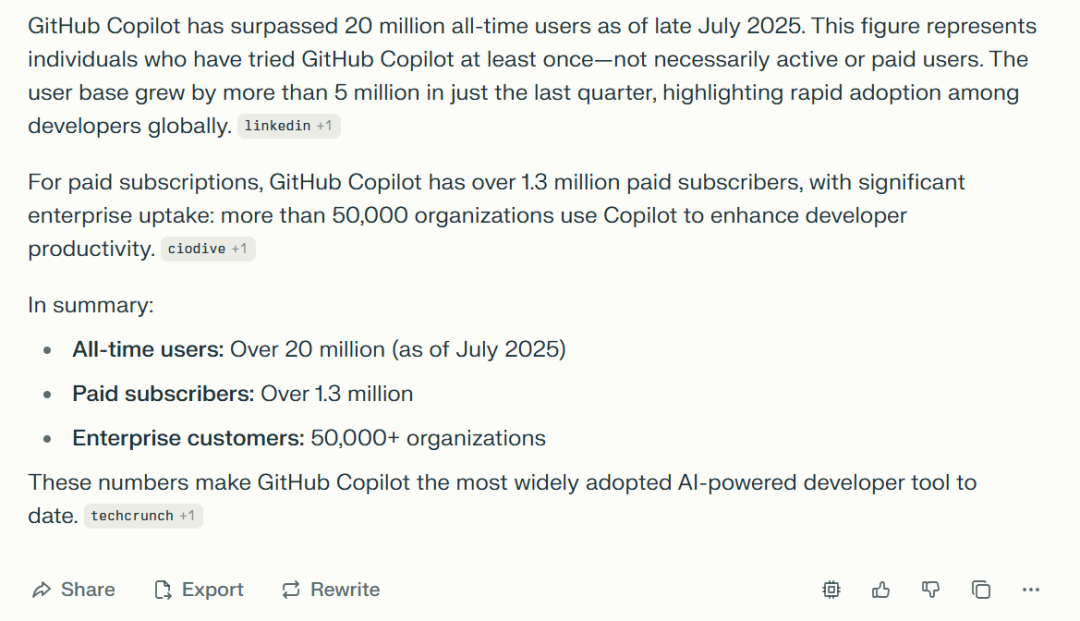
同样的问题,给到GPT-5,我想,很容易就不会被“误导”了。
回到正题,用户体量有限,但是ARP值很高的领域(上面说的终端工具),自然很重要。但是它就无法讲“互联网逻辑”,拼的就只是产品能力,而且在这个领域里,因为用户长时间的使用,所以能力高低清晰可见,用户也是没有黏性的。这个问题,其实对Anthropic非常致命,前面说了,它的APP和网页版应用的用户数就是增长乏力。更多的场景都在各种编程IDE中,例如Cursor,VS Code,Cline,Trae,等等。唯一原因就是Claude模型在代码生成方面的能力,一旦有模型真正在绝大多数场景的编程任务中超越它,就什么都没了。
三、国产“平替”
前段时间我曾经写过一篇:简单测试后的长文:GLM-4.5惊艳,MiniMax Agent不错,Kimi-K2还可以,DeepSeek亟待升级。他们都有自己想成为的样子,如同每年NBA选秀时,都会对新秀设定一个参考模板。很明显,GLM-4.5更像ChatGPT,MiniMax是一个被“Manus”深度影响的Claude,Kimi曾经想做Gemini,如今想成为Claude,QWen-3,它可能只想取代Llama……
我一直都不太习惯于使用“平替”,更不习惯成为“平替”,但是也会被问很多次,确实因为各种原因,国产才是更理性的选择。那我会选GLM-4.5,主要原因自然是更像ChatGPT,它的应用里,也最舍得给“算力”,思考也很努力,搜索也很努力。我只是有时候好奇,全球有千万量级的资深用户,不断在三大模型上提高付费率,可是又有多少愿意给到“国产平替”呢?我们真的只能依靠低价甚至免费来吸引客户吗?在一个token即收入更是成本的时代,这真的是正确的选择吗?
当然,很多人也会选择类似于豆包,还有DeepSeek,虽然已经半年了需要更新了,但还是用户体量巨大。有习惯,有所谓“用户体验”,可是习惯了“免费又好用”的“用户体验”的我们,也许对真正的“好”已经越来越缺乏判断力了。我们可以被信息流推送占据一天的绝大多数时间,却很少愿意让自己主动去搜索,去获取。AI在那里,压缩完的人类知识库就在那里,或许,免费的就是不值得“亲自”花时间去哪怕看一眼。