如果时间退回到2017年,AlphaGo震撼全球,紧接着,虽然AlphaZero具备更强的能力,从技术而言更令人“胆寒”,但引起的震撼却不如AlphaGo了。
同样的故事发生在了2023年的ChatGPT,GPT-4和一周多前的o1模型。不仅仅是因为遭到的待遇,更因为技术演进的路线。
如果说AlphaGO是靠“学遍天下棋局”而“具备”了战胜人类最顶尖选手的能力的话,AlphaZero则是靠“懂得”围棋的基础上“自我对弈”,自己进化的:它现在成为了最好的教练,而人类继续享受自己与自己对的美丽世界。
所以:
1、先通过学习海量数据得到基础知识,然后通过不断强化自己具备“真正的博弈能力”;
2、超越人类的智能存在,并没有严重威胁到人类自身;
对于GPT系而言,第二点我们暂且放在一边,第一点,几乎也是如此的。
一直到GPT-4,被大家熟知的概念都是预训练,transformer,scaling-law。可是似乎依然绝大多数人都不理解下面两句:
1、生成意味着理解;
2、大模型就是个知识压缩器;
可以有很多人跳出来批评说,将GPT与AlphaGO相提并论根本不对,预训练呢?transformer呢?scaling-law呢?
且不论“AlphaGO通过人类对弈数据训练就是预训练,AlphaGO也充分证明了scaling-law的存在”这两条,即使AlphaGO最早确实没有使用transformer,但是不代表没有通过类似的架构(只不过更早期,表现可能差一点)来让AlphaGO“理解”围棋,通过“落子”的方式。
生成意味着理解。虽然这句话依然面临很大的争议,但是上面描述的AlphaGO通过“落子”“对弈”来证明自己“理解”围棋,就是例证,回到大模型,通过生成来表示自己“理解”,也是同样的道理。
但是大家依然充满质疑,模型有幻觉,模型不可靠,模型经常错,连“9.9>9.11”这么简单的数学题都会错,怎么证明能理解?
其实,谁不会错呢?
大模型就是个知识压缩器,简单来讲分成两部分,预训练就是压缩的过程,下游任务(比如生成文字,图像,等等)就是解压缩并输出的过程。我们人还经常失忆,错误记忆,层出不穷,何况还是个“孩子”的模型呢?
一年前,我们可以把这种错误基本都归因于预训练,因为规模不够,数据不够或者错误,训练时间不够长,导致压缩的知识“损失率”很大。但是到了今年上半年,当Gemini-1.5,Claude-3.5,LlaMA-3一一问世,GPT-4自身也不断迭代后,这个判断,至少在文本类信息上,基本上过时了,不是说预训练的“压缩”完全正确了,而是我们大概可以认为知识“损失率”足够小了(然后,大家就简单的把它归结于“scaling-law失效”了,这又是个片面的结论,后面再解释)。
所以,简言之,至少在文本领域,“知识压缩”的预训练任务已经基本完成,那么,要强化的就是“输出”部分。如果说前者是大家通常认为的GPT(其实ChatGPT也是两部分都有的,GPT-4更是,任何能输出正常句子的模型都是)的话,那么后者,如今有了个独立的名字,o1,或者说一直传说中的“草莓”。这是所谓的精调也好、强化学习也好,Q*也好,作为一个独立的“模型”被正式推出,但它不是独立于GPT的存在,而是共生:GPT是知识外挂,是记忆体,o1是思考者(作家,数学做题家,研究员,等等)。
所以,根本不是o1出现证明预训练scaling-law失效了,而是在文本领域,预训练基本完成了它的历史使命。但是,预训练依然非常非常重要,还记得迟迟没有下文的sora吗,更大量的数据以图像、视频、声音甚至三维的形式存在着,transformer证明自己在这些数据形式上依然极有效,scaling-law依然存在,差的是数据是算力(不过算算门槛,你大概就知道能够参与其中的玩家两只手肯定数的过来了)。
回到文本数据预训练范畴,既然GPT-4等模型的预训练过程已经差不多证明了自己至少以很低的“损失率”完成了对知识的压缩,那么,如何输出就是重点,o1就是主角。
再回到“9.9大还是9.11”大这个问题,是的,就连早期版本的GPT-4(o)的回答也是错误的,因为它可能拥有了1.按位数表达数字的知识;2.基本的加减乘除的知识;3.比较数字的知识,但是当没有好的“大脑”时,就是没办法串联起来。所以错误 and 幻觉在所难免。
可是,我们如果回想自己当初如何学习比较小数大小知识的场景,大概会感叹一下,哦,原来这不是“天然”就会的,也是有方法的,我们也是一位一位比较的。
对了,把这个方法交给另一个模型,让它在GPT-4压缩过的知识上进行思考,就可以了,对,这就是o1模型的意义,也是在通向广义AGI道路上最后两个巨大阻碍的第一个。
所以,o1的团队会说他们花费了一年半的时间让模型学会数“strawberry”中有多少个字母“r”。这不是人教它规则,而是,再一次让scaling-law工作,当模型被训练足够多“范式化”的数据时,自己“涌现”出来了这种“思考”和“推理”的能力:GPT-4成为o1的“聊天机器人”与素材提供者,o1成为思考者,组织者,输出者。
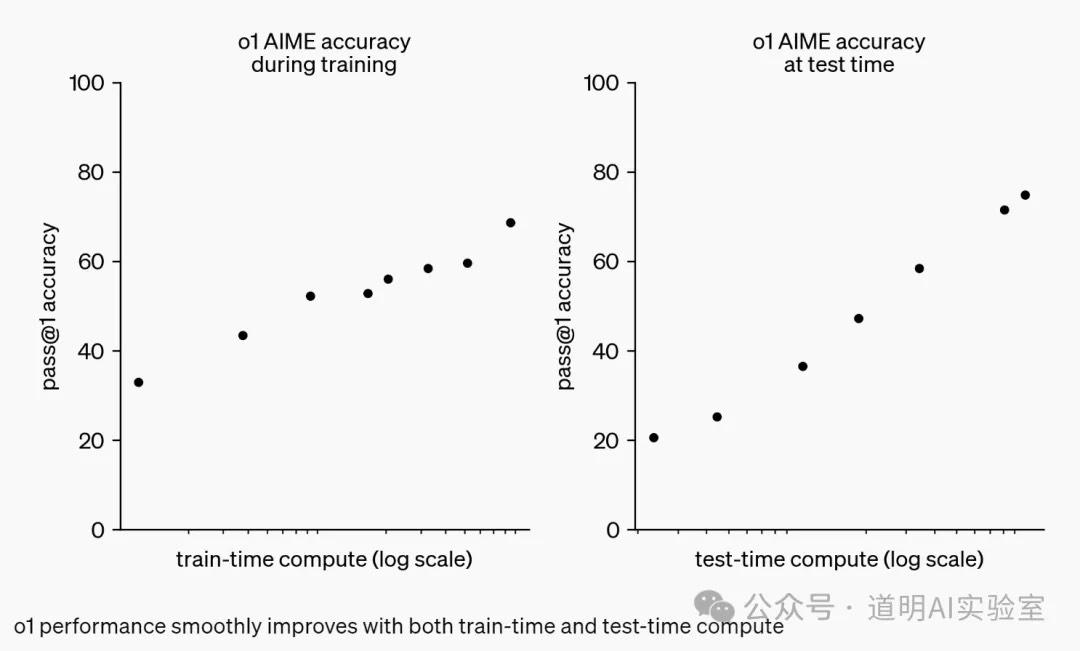
所以,会有下图,o1自我训练的时间越长,输出结果越好:scaling-law。
作为相互独立的个体,GPT(预训练部分)和o1各自都还有很长的路要走,预训练要去加入更多模态的数据,要去“理解世界模型”,o1要有更多的思考能力,逻辑能力,推理能力,嗯,自己训练自己的能力。o1依赖于GPT越来越多的知识,GPT海量的“知识储备”与潜力需要靠o1不断挖掘。
作为一篇公众号文章,到这里,基本就可以收尾了,但是依然需要回答很多朋友(同业)两个问题,这些问题的回答不是因为我有任何“独家信息”,我的所有判断都是基于公开信息、自己的经验和自己的实验得出的,这次也不例外:
1、GPT的命名问题,就是GPT-5还有没有?什么时候?我的答案,也许有,也许没有,但它真的不是很重要了,OpenAI一定是没想到ChatGPT会这么火爆,所以在通向AGI道路的不同问题解决路线上其实都是相对有序推进的状态。GPT一直就更像是内部工具或者给到其他开发者的基础工具的定位,如前所说,就是“知识压缩器”,只不过,现在需要压缩更多的其他模态的数据,例如图像、视频、三维,等等。随着时间的推进一定能够证明在这些数据上,transformer and scaling-law依然有效,只不过o1的“独立”面世,也意味着GPT-5还是GPT-6,数字就是个延续性的代号意义了。从某种意义上讲,我个人认为,如今让o1独立,而不是出一个叫做“GPT-5”的模型,是个很棒的选择;
2、算力问题。其实,大概最晚到今年上半年,大家基本上产生了一个共识,“大模型门票”已经抢完了,后面很难新增,反而还会有淘汰。因为门槛太高了,基础设施,数据,人,越往后越是天价。至于大家关心的算力需求问题,我只能说或许可以花点时间了解一下Oracle云(号称订购超过13万张B200)、AWS、Azure,Google云等等的大客户,大概可以得到相对清晰的结论的。我一直都是基于各种公开信息,结合自己的经验和实践,小心求证,不断修正。这大概跟“小作文”完全不搭边。