虽然市场依旧会质疑这一轮生成式AI的商业变现问题,但同时,更加不能否认的是:LlaMa-3的预发布掀起了新的一轮模型热潮,Microsoft、Apple纷纷发布开放模型,其中苹果的开放模型还是“真正开源”的;Google和Microsoft的财报显示出了AI对云业务的强大拉动作用,更给出了继续加大基础设施投入的决心和AI能够继续带来收入增长的信心。
几乎一夜之间,情绪又从悲观开始向乐观转变。
可是,正如线下交流时一直说的一样:momentum一直在;看起来模型的进步曲线变得有所平坦,但是以GPT-5为代表的下一代模型正在路上,虽然发布时间依然面临不确定性,但是模型基础能力的跃升是可预期的(尽管,这种reasoning能力上的提升并不会像sora这类模型那么令绝大多数人眼前一亮)……
我们更多看到的是,模型作为生产力工具已经被越来越多的应用到各个领域,而且开始了从科技公司向非科技公司的渗透进程,无论是云业务的高增长还是大家对推理成本和手机端模型部署的更高关注,都意味着落地爆发即将开始,虽然,这是模型落地爆发,而不是“AI应用爆发”。
梳理近期三个方面的内容,不难发现即将到来的趋势变化:
一、LLaMa-3、Phi-3、OpenELM、Qwen1.5-110B开启“开放”模型热潮
为了避免概念模型,从现在开始,将普遍称呼的“开源模型”分为三类:
- 开放模型:是指仅开放模型权重供下载及几乎接近于完全的免费商业使用许可,开发者可以下载模型,部署到本地,在离线环境下运行,但是模型训练的细节和数据则并不公开,代表就是Meta刚发布的LlaMa-3,Microsoft紧跟LlaMa-3发布的Phi-3;
- 开放训练代码,不开放数据:曾经的LlaMa模型完全开放了训练代码,甚至也提供了完全公开的数据。从最近很短一段时间模型演进的趋势看:模型架构已经逐渐稳定,越来越多的生成式数据加入可以提高模型的能力,预计,未来,开放代码但是不开放数据会逐渐成为一种主流的方式;
- 完全的开源:即不仅开放训练代码,还开放使用的数据,以及模型的权重。最新的代表就是Apple的OpenELM模型,还有之前的OLMo;
确实,3中的完全开源更符合软件开源的最完整定义,但是,如今的大模型训练,即使是很小规模的模型,所需要的算力也不再是个人甚至中小创业公司可以达到的了。开放代码和数据的意义不再是为了降低门槛,而更多是为了研究和应对未来可能的风险准备的了。
对于很多应用而言,即使是1的开放权重,只要商业应用许可没问题,实用性还是比较强的。当然,正如上文所说,也有越来越多的模型正在选择开放训练代码和少部分开放数据,选择2的方式,毕竟,当高质量数据和生成数据成为决定模型质量高低的最重要因素时,训练代码的开源,可以给到开发者更多的信心和正向反馈,帮助模型更快进步。
上周发布的LlaMa-3在社区不仅掀起了如下图的热潮,更是带动了一波开放模型发布的热潮。
仅仅引起足够关注度的的就有Microsoft的Phi-3,Apple的完全开源模型OpenELM,阿里的Qwen1.5-110B。
正如我在4月1日的文章标题一样:开源模型的表演时间开始了。
开源模型表演时间开始,推理市场正式开启
篇幅关系,这里略过每个模型的优缺点分析了,直接给出综合这些模型特点,得到的新启示:
- Scaling Law当然依旧有效,但是呈现出了不同于2020年OpenAI论文中的曲线特性。下图是OpenAI在2020年论文《Scaling Laws for Neural Language Models》中关于模型参数、数据和模型损失率之间的实测关系,正是这个实测的曲线让研究者得到了两点共识:参数规模和数据的增加都能提高模型表现;参数规模和数据量应该匹配。
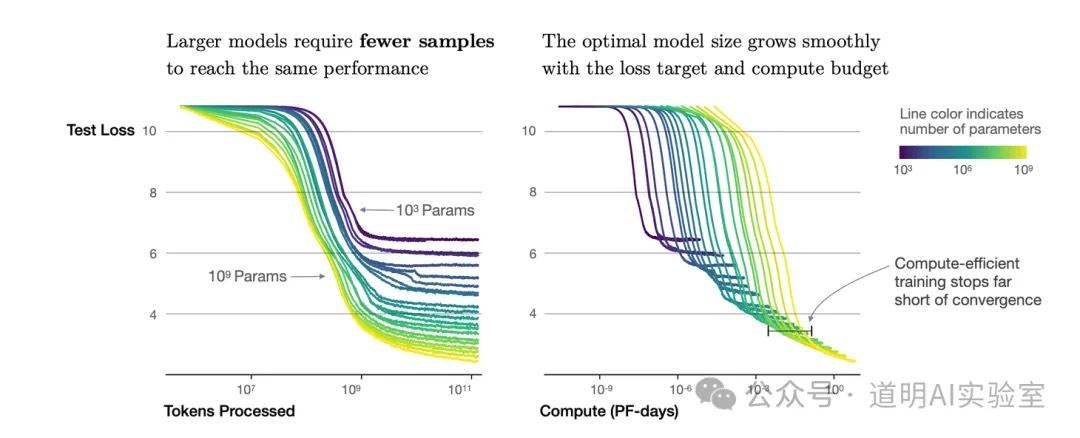
然而,无论是LlaMa-3还是Phi-3,都给出了新的结论,在模型参数规模固定的情况下,仅仅大幅提升数据量,就能让小参数模型超越更大参数模型的表现:LlaMa-3的训练数据量从前一代的2T增加到了15T,Phi-3的训练数据量则是3.3T,新版模型的表现均得到了大幅提升。虽然类似于上图的随着训练数据量提升,损失率下降的速度从几何级数收敛到log的曲线形状并没有改变,但是曲线明显在x轴上放大了:二阶导和一阶导拐点更晚到来意味着同样模型可以容纳更多的训练数据;
合成数据的作用越来越大。就在前段时间,大家普遍还都担心“互联网数据枯竭”的问题,如今Phi-3提到了训练中合成数据发挥了重要作用,LlaMa-3团队的结论很有趣:利用LlaMa-2生成的数据可以训练数据质量分类器,对训练数据进行严格筛选。那么这意味着数据门槛下降了吗?恰恰相反,数据门槛大幅提升了,因为如何生成足够多的高质量合成数据反而会成为未来最重要的know-how;
用更小规模参数模型训练更多的数据,一方面进一步提高了训练的算力门槛,但是另一方面又大幅降低了推理部署的门槛和成本。我知道,进一步讨论大模型和小模型的问题可能会带来不少不必要的争议,但是仅看LlaMa-3披露的信息,8B版本的模型使用了130万个H100的GPU小时,而上一代LlaMa-2模型里70B版本训练只是使用了170万个A100的GPU小时而已。还是那句话,明白其中差别的自然明白;
是的,我们即将会看到:1、各种模型的衍生版本漫天飞扬;2、端侧部署变得极容易,模型效果也达标;3、手机本地跑模型已经是现实,而且会被快速优化,如果一定需要找一个AI应用落地大规模加速的场景,那就是手机。
二、模型训练是知识压缩过程,模型推理是解压缩过程,人人拥有模型即将成为现实
虽然,“大模型就是知识的压缩”这句话已经被反复提及,然而在很多交流的过程中,我发现对“压缩”含义理解的比例并不高,认同的则更少。
我们往往将注意力放在了“GPT可以自己写文章,Sora可以自己生成电影”这样表观的震撼效果上,却反而忽略了生成式AI最初的目标:知识容器,当传统的符号人工智能方法无法通过更巧妙的方法穷尽更多“知识规则”时,通过将深度神经网络作为容器,将表层语料压缩进容器,并让模型涌现,自己获得知识,就成为一个更可行的选择。
是的,从训练的任何过程看,我们都很容易得到一个结论:大模型本质就是概率,甚至我都一度这么认为。但是,过去一年大量的研究也不断在证实一个推论:模型提取出了大量的“知识”,并具备了基本的推理(reasoning)能力。
这些也都在不断坚固着一个信仰:模型可以生成意味着它理解。
去年11月份,在看完OpenAI开发者日的直播后,我很兴奋地写下了一个标题:如果每个人都拥有大模型。模型部署门槛的快速降低,也许会在很短的时间里让梦想成为现实。
如今再去看这个梦想,又多了几分更多的认识:
- 如果模型就是装在知识压缩后的容器,人人拥有大模型,也意味着每个人都有了知识外挂;
- 是的,生成式模型可以回答我们的问题,增强搜索功能,作为copilot角色帮我们完成知识整理、文档撰写、程序开发甚至影视游戏创作,作为agent可以帮助我们完成许多任务;
- 然而,专属个人的生成式模型,或许还意味着可以按照我们的想象创作出各种各样的环境或者“世界”,解压缩的过程其实就是创造一个又一个“世界”的过程;
- 我们可以在这些世界里展开无边的想象力,也可以,在这些世界里训练真正的智能;
- 这个过程,是更多模型开发者设想的达到通用人工智能AGI的可能的探索道路;
- 如果依靠现在模型的生成能力已经能够大幅提升我们的效率,那么,在模型创造出的足够多的“世界”中摸爬滚打出的智能,哪怕不会在短时间里达到甚至接近AGI,但也可以再次升一个维度,换一种方式重新震撼人类;
- 很可能这个hyper cycle中就是会连续经历两次升维:生成式AI的“无中生有”,生成式世界中智能的“涌现”;
- 这大概也是为什么Altman(OpenAI CEO)会在前几天的演讲中会提到很多着眼于弥补现有模型短板的研究和产品会在未来更智能的模型出来后会被淘汰(Many current ventures and research endeavors are predicated on rectifying AI’s shortcomings. However, with the advent of advanced models like GPT-5 and GPT-6, such efforts may become obsolete);
我相信的是,transformer帮助我们更好的对信息进行压缩,scaling law让模型产生“知识”概念,目前,这些工作已经完成的很好了,无论是更好的“解压缩”效果还是快速降低的获得门槛,未来,这些工作当然还将继续进步。但是,生成式AI是通向AGI道路上非常重要的基石,而一个新的时点可能正在快速接近:成长于生成式基石之上的智能。
生成式的世界,AGI,万物计算,元宇宙,看不到头的算力需求增长,这些许多人眼中“忽悠”成分十足的概念,都在这个维度上逻辑统一。一个远大于过去任何时代的维度,尽管,评估移动互联网(权且认为是当前的时代)总量上的规模依然不是件容易的事情。
三、大规模生成的前提就是计算变得更便宜,云与边缘是看起来最可行的方向
压缩消耗算力,解压缩更消耗算力,生成的过程就是一个算力消耗的过程。
算力成本,既是生产的成本,也是资源的消耗,也许在未来某个时间点,我们会找到更有效的计算方式。可是,虽然人类进行生物计算消耗的能量极低,但是地球为了维护人类存在付出的资源代价已经是天文数字。相比之下,即使再乐观的推算,未来五年里,生成计算的消耗也很难超过5%。
但是,我们总是会更在意这些可见的成本。模型解压缩(推理)成本也是当下除了模型能力之外最重要的课题,这个问题也几乎占据了我过去一个月讨论内容的一半:
- 开源LLaMa-3,英伟达GB200,与推理
- GB200推理性能的三十倍提升如何得来?
- 推理成本,与开源
- Cohere发布面向企业端模型,推理成本成为下一阶段关键
抛开技术层面的讨论,从经济角度出发,在一个巨大群体里降低商品使用成本的最有效方式只有一种:共享。
如果我们需要通过更大规模的硬件(英伟达刚发布的的GB200 NVL,或者以后不断会发布的新硬件)来大幅降低整体使用成本,从而降低每个个体的使用成本,云就是最好的方式。
我们看到的无论是Microsoft还是Google财报中云业务的增速提升虽然可以部分归结于他们拥有更好的模型,但更多还是因为这是企业或者个人使用模型的成本最低方式。
当然,走向另一个极端的方向也是可行的,并且趋势正在出现:将模型部署在尽可能便宜的硬件上,例如手机。这需要模型更好的压缩能力(更小参数规模获得更强的能力),以及更好的硬件与模型适配性。如第一部分的讨论,这件事情,正在发生。