过去一段时间,我关注的点集中在以下几个方面:
1、开源模型能力不断提升,意味着什么?
开源模型表演时间开始,推理市场正式开启
推理成本,与开源
2、我们需要什么样的AI?
我们需要什么样的AI(一)?——生产力工具
我们需要什么样的AI(二)?——从GPTs热潮褪去说起
3、如果模型能力达到了,那么推理市场又会如何?
Cohere发布面向企业端模型,推理成本成为下一阶段关键
GB200推理性能的三十倍提升如何得来?
如今,开源版本的LLaMa-3来了,仅仅一天多的时间,各种基于LLaMa-3精调的模型如雨后春笋般涌现:拥有一个接近GPT-4水平的开源模型,是整个社区期盼已久的;如今真的到来的时刻,对开发者的刺激度,根本不亚于当初ChatGPT发布时刻。
虽然,为了试验,我还在Intel Meteor Lake上艰难的跑着INT4的量化程序。但是,在hugging face上已经有了基于LLaMa-3的MoE模型:4x8B。
看起来,四个专家领域分别侧重于:聊天、代码、助手和思考。
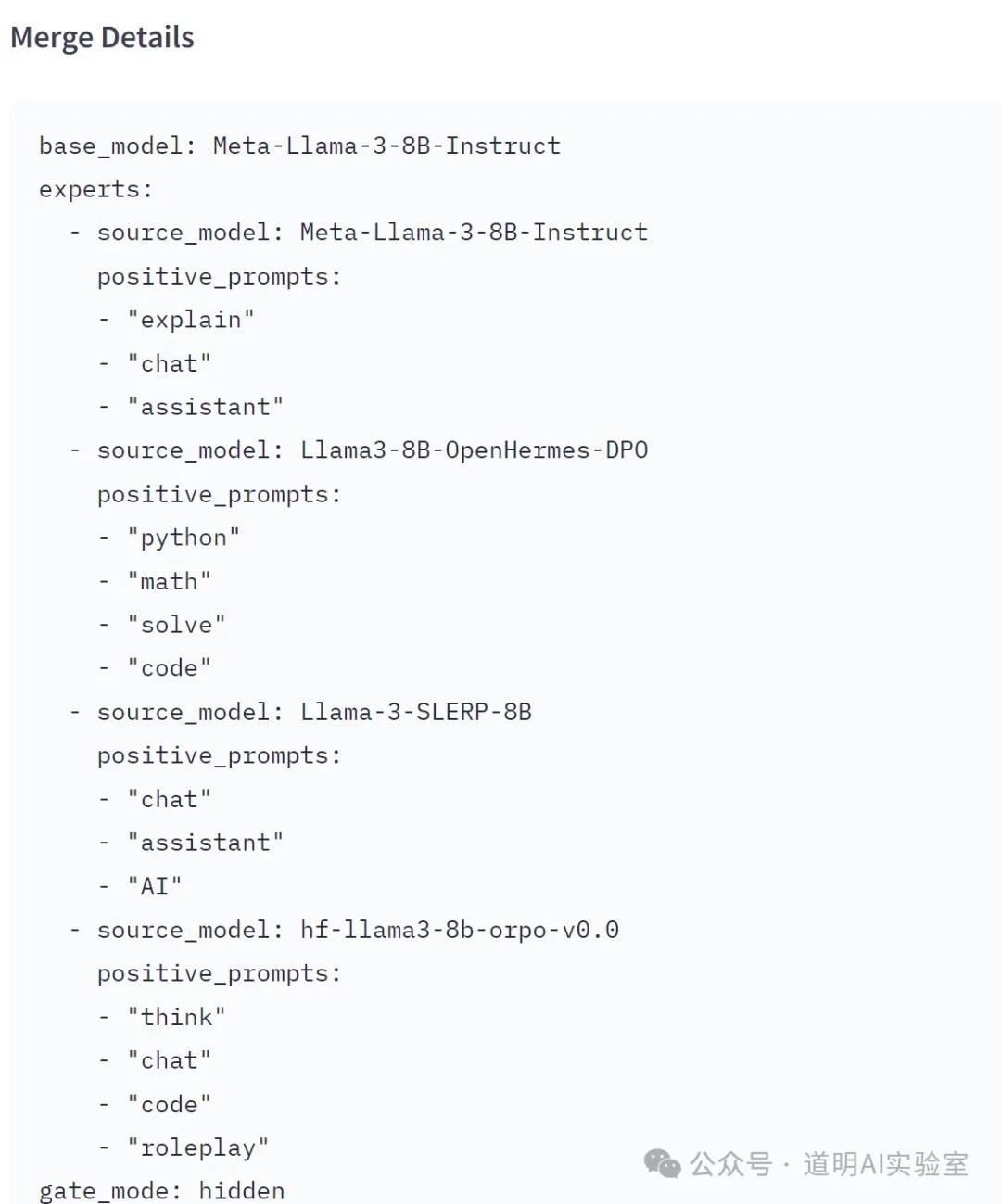
当然,这个模型效果估计不会太好,毕竟,这么短的时间,只是跑通技术,真正增强能力的精调或者优化,还是需要一定时间的。
但是,我们可以明显看到,基于现有模型架构应用的技术栈已经趋向于成熟:在保证推理性能的算力支持下,好的基础模型可以即插即用。
这大概越来越成为更多人的共识,所以才会有我开篇时候列出的这段时间考虑的问题以及作为思考过程记录下来的文章,而下面是我考虑这些问题的基本逻辑脉络:
1、模型进步了,无论开源还是闭源,都会带来更多的应用场景,只是我从来不认为AI应用是低门槛的工作。部分因为这个原因,我们也会看到海量的企业端或者个人私有化部署。推理成本是所有人必须首先考虑的问题;
2、作为个人,用PC进行推理很酷,自己打造个性化的AIPC,既有实用场景,更有巨大的延展空间;但是,对于团队协作而言,云是不二选择;
3、那么,对于团队和公司而言,在模型满足要求的前提下,token的吞吐量是最关键的指标,因为,需要的token数/吞吐量*云价格,就是成本,这还是假设24小时不间断吐token的前提下;
4、我发过databricks关于不同硬件token吞吐量和成本计算的讨论,基本结论是,虽然有很多非硬件方法压减推理成本,但是在现有的算力上,成本依然很高;
5、如果我们不选择私有化部署的开源模型,而是直接调用商业模型(可能开源,也可能闭源)的API,token费用也非常可观,比如GPT-4是每一百万token收30美金;
6、如果说英伟达靠极端的互联技术使得训练大规模神经网络模型成为可能,并加速了GPT-3这种级别模型的落地,那么如今的GB200 NVL72是英伟达再次利用极端的互联技术,使得推理成本快速下降成为可能,我初步测算是至少下降4.8-6倍:GB200推理性能的三十倍提升如何得来?
7、不是谁都有那么大的模型需要用GB200 NVL72集群去推理,但是基准成本的快速下降,会带来所有推理成本的快速下降,至于怎么做,云服务商会去思考;
8、所以,会抢吗?见仁见智吧;
9、如果LLaMa-3带来模型基准能力的大幅提升,那么,小规模参数的模型能力也会大幅提升(无论是用更多的数据scale,还是用教师-学生模型去知识蒸馏),其实,手机端推理能够带来的应用想象力更大;
10、大概总会有这么个过程:因为出了更好的模型,更好的模型都是更大算力的结果,然后出了够好的开源模型,开源模型部署方式很灵活,所以端侧和边缘侧部署具备想象力,如果都要用,那么应用会爆发,如果应用会爆发,那么缺数据,对了,“版权也很重要”;
第十条,给“懂”的人。