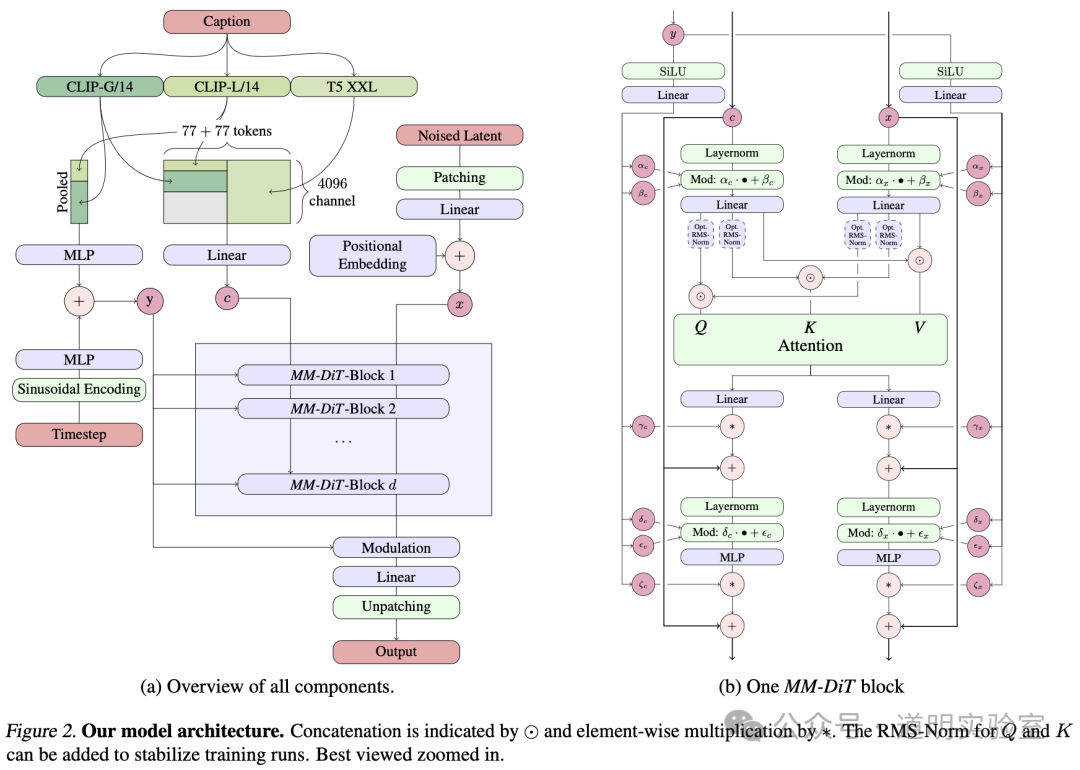
下图是Stable Diffusion 3的模型架构图,照例,是要写一下关于这个模型的评价的。
是的,这个架构很精巧,用了两个DiT,简单讲,其中一个负责图像,另一个负责文字,然后融合;复杂一点说,那个负责文字的不是只是文字那么简单,而是用到了CLIP等模型,CLIP模型可以简单理解为一个文字与图像对应的模型。
所以,这个模型,应该会具备更好的文字理解力,能够支持更复杂的提示词,引入DiT,也能从结果上保证较好的一致性。
另外,这样的架构,可以很方便的扩大规模,也可能可以达到“涌现”的拐点。
问题是:至少超过99%的人,包括我,无法复制这个模型。
对于二级市场投资而言,这不是一个问题,可复制的标的,往往也没价值。一切看结果就可以。但是,这个领域的特点是:变化从来不是可持续跟踪的,因为曲线不是连续,而是一个又一个脉冲。
然而对研究,或者希望依托所谓AI能力开拓新商业机会的多数人而言,这是一个无比恐怖的状态:突然“有”机会,突然就“game over”了。
英伟达股价在过去两个月又飙升了接近一倍,Stability.AI这样的公司都排不到资源,只能在官网公告新建了利用4000张英特尔Gaudi2算力卡搭建的集群已经就位。
算力自然是拦住绝大多数人的门槛之一。数据呢?更加是了。
Transformer被证明具备极强的规模可扩展性,但是在小规模和小数据上,效果却不如之前的传统模型。也就是说,如果没有超大集群和无可估量的数据量,我们,无法从过程上见证“涌现”。
OpenAI走向Close固然是处于各种考量下的一种选择,但事实上,模型训练其实已经走上了快速封闭的道路,只是,因为训练所需要的时间,外面人看到结果显化,就已经有了时滞。
模型训练越来越封闭,不代表开源竞争力减弱,更多的公司和个人会坚持“开源”,即是竞争策略,也是为了获得更多的专业反馈。
也许,越来越多的人,只能放弃“幻想”,选择成为Cohere定义的“Independent Researcher”,为“大模型”打工,而不是妄图理解甚至掌控。
垂直与“小数据”?如同一口井打了几米,发现地下水位正在快速的上升,垂直的一口口“竖井”刹那间就被漫出地面的大水连成了一片海洋。