
“AI之父”杰弗里·辛顿最新演讲:数字智能将战胜生物智能
被誉为AI之父的杰弗里·辛顿于2024年2月19日在牛津大学做了一次题为“Will digital intelligence replace biological intelligence?”(数字智能会取代生物智能吗?)的演讲。
37分钟不到的演讲,或许会有不少人认为观点并不新鲜,但是抛开AI风险的讨论不谈,辛顿思考的角度,对于数字智能和生物智能的理解,以及对于训练计算基础架构的新想法,确实启发很大,甚至让自己整夜都在反思:我觉得大模型有没有人眼中的“智商”不重要,老爷子认为非常重要,因为这决定了AI研究发展的方向,而且,他相信,现在的模型有“智商”,他“坚信光”。
如今看视频,都会让Gemini Ultra 1.0也看一下,并做出摘要,截图如下。想看原视频的朋友也可以直接通过截图中的链接访问。
这当然是GPT-4暂时还不具备的能力。当然,上面的总结有明显的错误,比如时间地点,其实这是因为视频完全没有交代相关信息,可以看作是“幻觉”,但是恰好对于这个问题,辛顿在视频中有不同的解释,我觉得这段很精彩,在后面的解读中,会提到。
虽然多数人公认GPT-4能力更强。但在我日常工作学习甚至生活中,GPT-4已经逐渐淡出了,原因很简单,GPT-4推理能力再强,在目前的场景下,还不足以代替我“思考”,而Gemini Ultra却是一个更好的工具和执行者。
以下,就是我摘录了辛顿演讲PPT的绝大部分内容(关于风险与威胁的部分因为各种原因略去),简单解释,并同步给出自己的粗浅想法:
1. 概览

因为这是概述的缘故,所以我直接把上面这一页交给Gemini翻译。同时,因为是在Gemini分析视频的会话中上传了这页PPT(带有背景知识),所以Gemini“超额”完成了任务,截图如下:

2. 两种不同的智能
很精辟的比较:
- 生物智能需要先理解怎么学习,然后去推理;
- 数字智能由逻辑驱动,必须先知道知识如何表达,然后再学习。

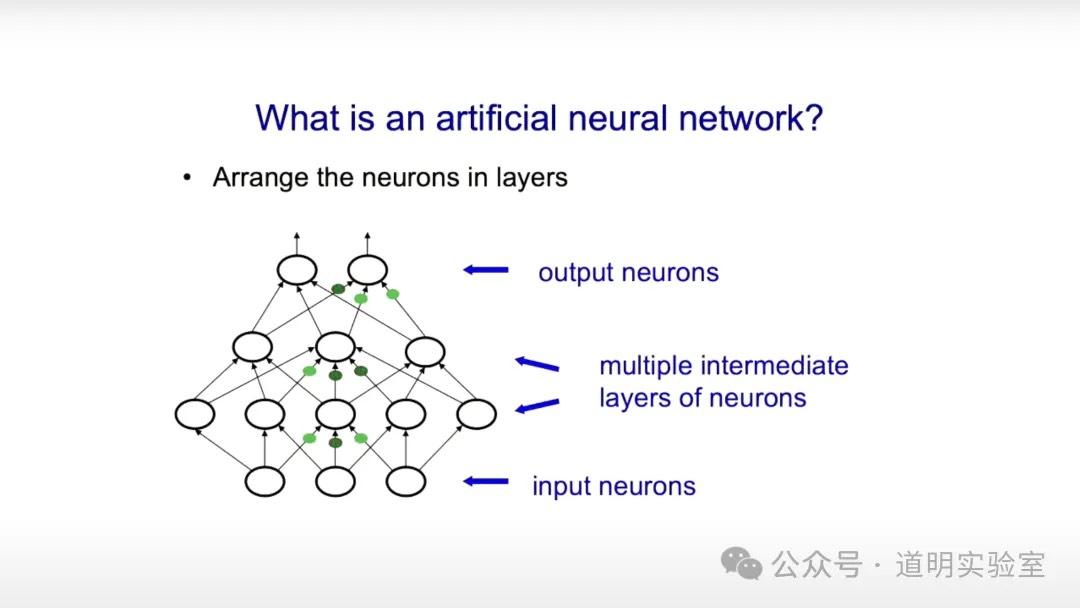
3. 人工神经网络的解释
这个很基础,简单而言,就是模仿人的神经元,形成一个网络,给出输入,得到输出。
4. 低效的神经网络训练方法
在神经网络里,每个神经元都是一个函数,整体构成了一个复杂的矩阵计算,同样的输入条件下,每个神经元上的“权重”直接影响输出结果,权重在这里等同于参数。
低效的神经网络训练方法,就是类似于基因突变(mutation)的方式,微小的调整某一个权重,然后看得到的输出是否有帮助,如果有,就把结果保留,等待下一次“突变”。这种近似于“靠天吃饭”的方式,自然是一种极其低效的“训练”方法。

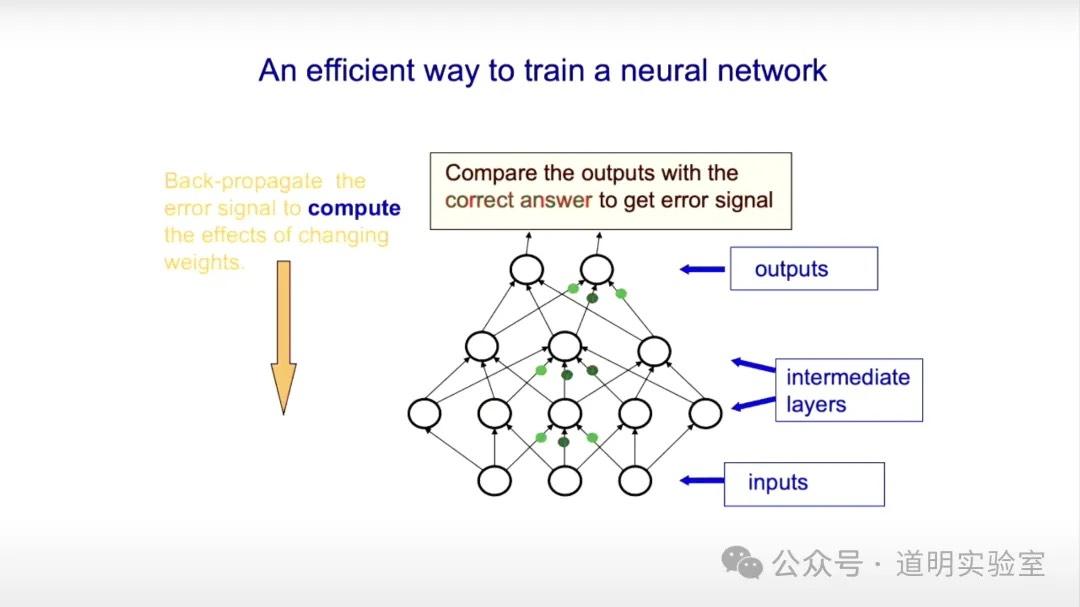
5. 一种有效的训练方法
有效的方法就是利用反向传播(back-propagate):每次调整一批权重,然后把得到的结果跟正确的结果做比对,根据比对结果决定下一次权重调整的方法(最常用的是最快梯度下降法),直到神经网络输出的结果与正确结果之间的偏差小于一定值之后,就认为训练完成。偏差计算的方法,被称为损失函数。神经元上的函数又被称为激活函数。
6. 识别图片中的对象
显然,即使现在,这都是一个生物神经网络(生物智能)更擅长的任务,因为分层次的特征识别能力非常适合这种场景。

7. 深度神经网络的崛起
2012年,通过反向传播方法训练的深度神经网络AlexNet对1000个不同类别的物体图片进行分类时,只有16%的错误率,远胜过之前最好模型的25%错误率。这个成果发布后,深度神经网络开始全面取代其他算法,而辛顿被称为“AI之父”,最重要的原因就是他对于深度神经网络的开创性贡献。

8. 语言理解的争论
早期在对语言的理解上,有很多怀疑的声音。语言学家Chomsky认为人类天生具备语言理解能力。符号人工智能(Symbolic AI)社区认为基于特征提取的算法永远不能理解语言。

9. 符号 vs. 心理学定义
在符号人工智能眼里,词就是它与其他词的关系。心理学上,词就是一系列特征,近义词有相似的特征。

10. 1985年的小型语言模型
辛顿在1985年做了一个模型,试图统一这两种定义。核心思想是:通过预测下一词不断生成句子,这就是知识。这是如今GPT诞生的源头。

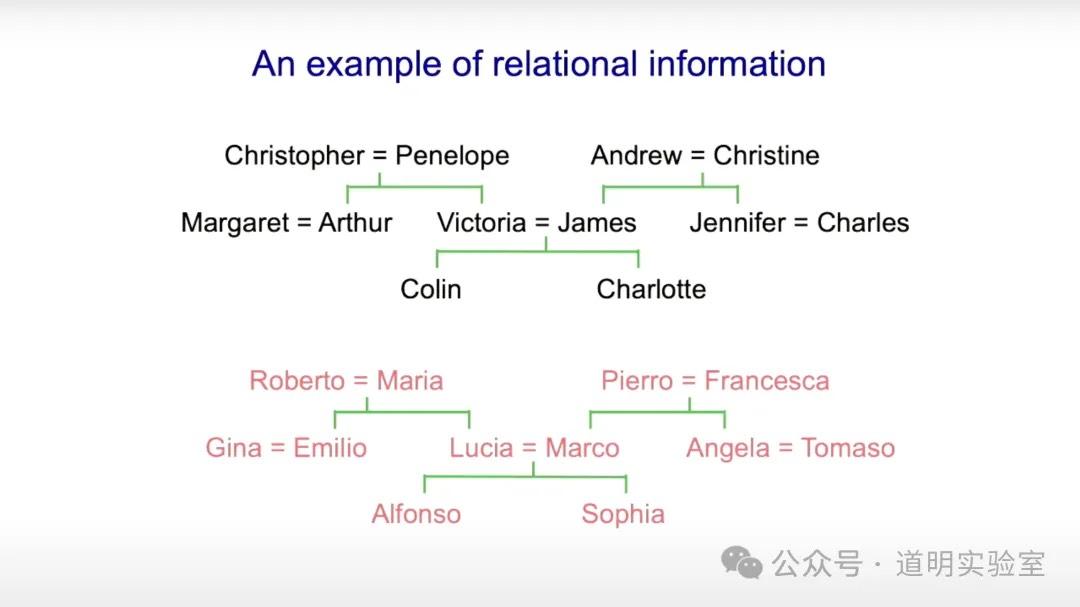
11. 族谱案例:规则提取 vs. 神经网络
如果是符号AI,需要提取规则(如“X的母亲是Y”+“Y的丈夫是Z”=“X的父亲是Z”)。但在实务中这越来越难操作。


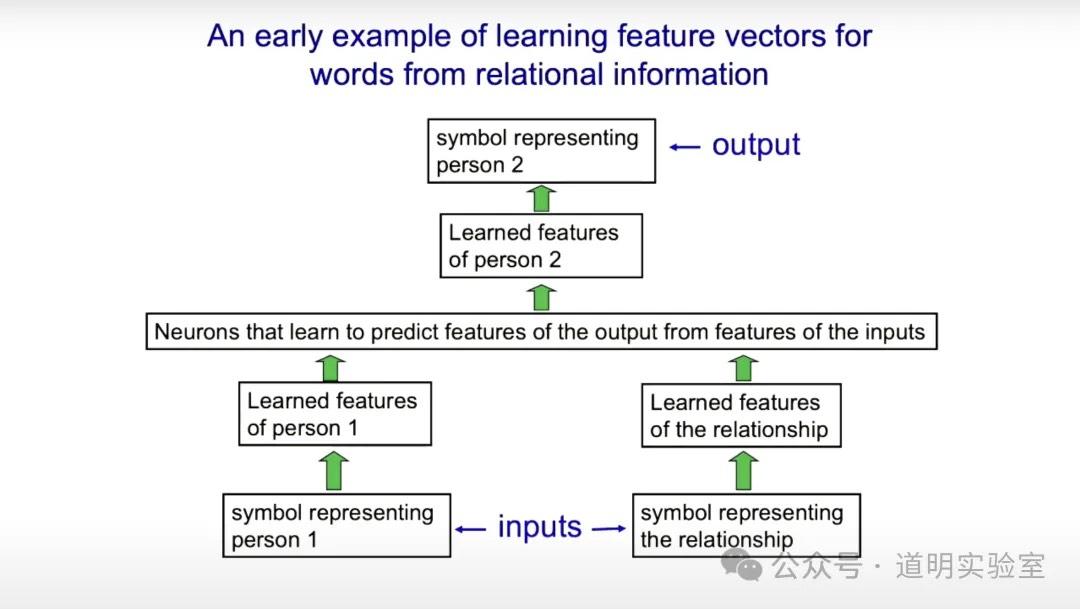
12. 向量表达与预测
神经网络通过学习特征向量来表达人和关系。输入“人”和“关系”的符号后,神经网络能“预测”另一个人的符号。

13. 大语言模型(LLM)的理解能力
很多人认为LLM只是高级的自动完成机。辛顿反驳称,LLM能生成下一个词,意味着它已经学习到了足够的特征及关系,意味着它已经“理解”了。LLM没有储存文本,它是通过“学习”来预测。


14. “幻觉”还是“虚谈症”?
辛顿认为LLM的错误应被称为“虚谈症”(Confabulation),即心理学上人类对自己或世界产生的记忆错误。人的大脑也是通过权重存储知识,细节往往会错。他举了John Dean的记忆作为案例。


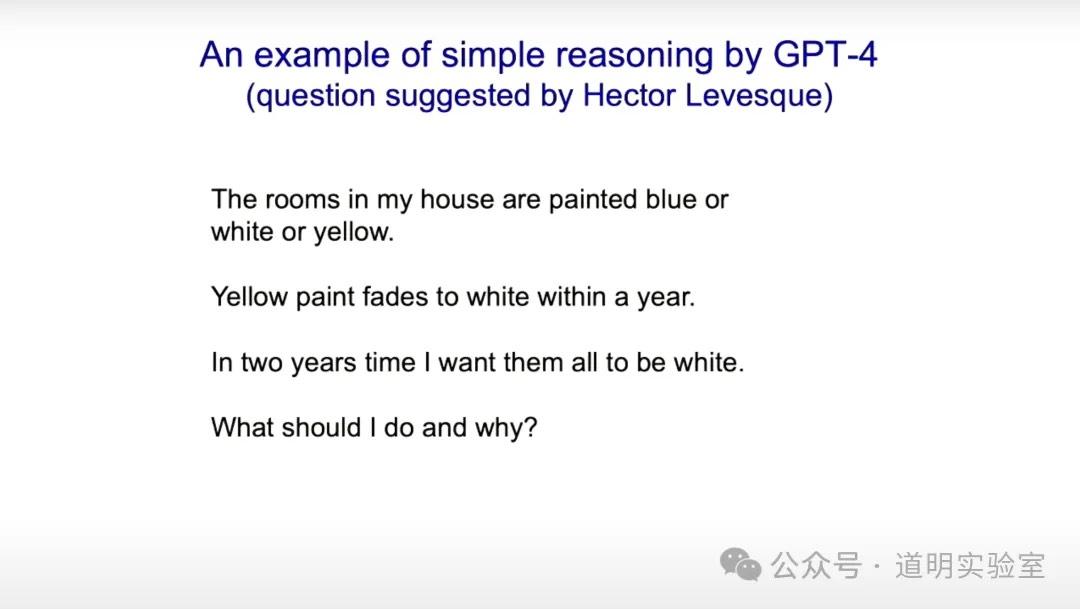
15. GPT-4 问答示例
辛顿展示了一个GPT-4问答的例子,证明其推理与理解能力。

16. 数字计算与“逝存计算”
- 不朽计算(Immortal Computation):软硬件解耦。权重不随硬件损坏消失。基于二进制、离散的数字系统保证了可靠性。

- 如果软硬件不再分离呢?在AI时代,程序是“学习”出来的,“模糊的正确”挑战了软硬件解耦原则。

- 逝存计算(Mortal Computation):放弃硬件精确性,允许低能源下的模拟计算。虽然硬件损坏知识会消失,但计算效率可能极高。


- 解决知识消失的方法是“教师-学生”模式(蒸馏)。生物智能间的蒸馏(如教学)非常低效,而数字智能可以通过MoE架构高效分享知识。



17. 结论:二十年内,数字智能有50%概率超越人类
生物智能在能量约束下演化。数字智能一旦解决能源问题,将因其卓越的知识共享能力全面碾压生物智能。辛顿认为,在二十年内,数字智能超过生物智能的概率大概是50%。

我的感想
过去,我一直认为GPT-4这类模型只是输出能力强,并不存在人类意义上的“理解”。然而,在辛顿看来,AI模型一定是因为“理解”才有预测能力。他相信AI需要“理解”,否则这条路走不通。自从辛顿离开Google后一直提示AI风险,或许正是因为他真的“相信光”。
碳基与硅基之争,归根结底是对能源依赖度的不同。在物理场地和能源约束下,MoE确实成为了主流选择。Google的Gemini 1.5也是MoE架构。
辛顿说的“超越”,是一个更科学、更彻底的概念:一个新物种在“智商”上全面碾压。这与工程上的AGI概念有所不同。他“坚信光”,认为证明大模型有没有“智商”极其重要。